Model Building
The first step in model building is to get the data and split it into 'train', 'test' and 'validate' sets and then start building the model.
What is a Model?
A specification of a mathematical (or probabilistic) relationship that exists between different variables. For example, on a platform that uses advertisements for revenue, a relationship might be modeled as:
- If you have more users on your platform, then your ad revenue is also higher.
- An email with characteristics like a missing 'to' address and words like 'FREE,' 'URGENT,' or 'JACKPOT' in the subject or body is likely spam.
What is Machine Learning?
Machine learning is the process of creating and using models that are learned from data. These models are then applied to real-world applications to enhance business value.
Here are some typical examples of the results that a model can achieve:
- Predicting whether an email message is spam or not
- Predicting whether a credit card transaction is fraudulent
- Predicting which advertisement a shopper is most likely to click on
- Predicting which football team is going to win the Super Bowl
Model Building Methodologies
Broadly speaking, the model building techniques can be classified into:
Supervised Learning: In this approach, the model learns from data that is already labeled with the correct outcomes.
Examples:
- Deciding whether to issue a loan to an applicant based on demographic and financial data (with reference to a database of similar data on prior customers).
- Identifying a network data packet as dangerous (virus, hacker attack) based on comparison to other packets whose threat status is known.
- Predicting whether a company will go bankrupt based on comparing its financial data to those of similar bankrupt and non-bankrupt firms.
- Automated sorting of mail by zip code scanning.
Unsupervised Learning: In this approach, the model learns from unlabeled data, identifying patterns and structures on its own.
Examples:
- In an online bookstore, making recommendations to customers concerning additional items to buy based on the buying patterns in prior transactions.
- Identifying segments of similar customers.
- Estimating the repair time required for an aircraft based on a trouble ticket.
- Printing of custom discount coupons at the conclusion of a grocery store checkout based on what you just bought and what others have bought previously.
Reinforcement Learning:
Reinforcement learning (RL) is a goal-oriented learning method. An agent learns to perform actions in an environment to maximize a cumulative reward. The focus is on finding a balance between exploration (trying new actions) and exploitation (using known actions that yield high rewards). Partially supervised RL algorithms can combine the advantages of supervised and RL algorithms.
Prerequisite for Model Building Step
A model is only as good as the data you feed it. This is often summarized as "garbage in, garbage out." The first set of steps you take is very similar to the EDA procedure and can be summarized as below:
- Get substantial data.
- Identify and decide on the course of action for outliers: remove, keep, or fix. Finding outliers could be the main purpose of certain business scenarios (e.g., airport security screening). This is called 'anomaly detection.'
- Impute or drop missing values - a big exercise by itself to decide on which one to adopt.
- Data sanity check - E.g., dates in multiple formats to be fixed, start date should be before the end date, etc.
- Normalize or Standardize Data - this technique uses a scaling function to bring all variables to a similar scale so that variables with larger ranges won't dominate and skew the model.
Common scaling techniques include:
- Standardization (Z-score Normalization): Subtract the mean and divide by the standard deviation.
- Normalization (Min-Max Scaling): Subtract the minimum value and divide by the range (max - min).
Partitioning the Data
Once the data is ready with all its preprocessing, the next step is to partition the data into three (some folks go with two) parts:
- Training Data: Used to build the model.
- Validation Data: Used to evaluate and tune the trained model.
- Test Data: Used for a final, unbiased evaluation of the model after the validation phase. While some practitioners merge the validation and test sets, maintaining a separate test set is a best practice to avoid biased performance metrics.
Once the model is found to be satisfactory with the given data on hand, you can start exposing the real world production data to deploy the data science solution!

Problems with Models
Okay, you followed all the steps and created your Model and it works great with your test data, however when it is deployed to production, it is functioning poorly! What could have gone wrong?
If your model is working well with your production data then the model is fitting well.
Otherwise, it is likely one of two common situations:
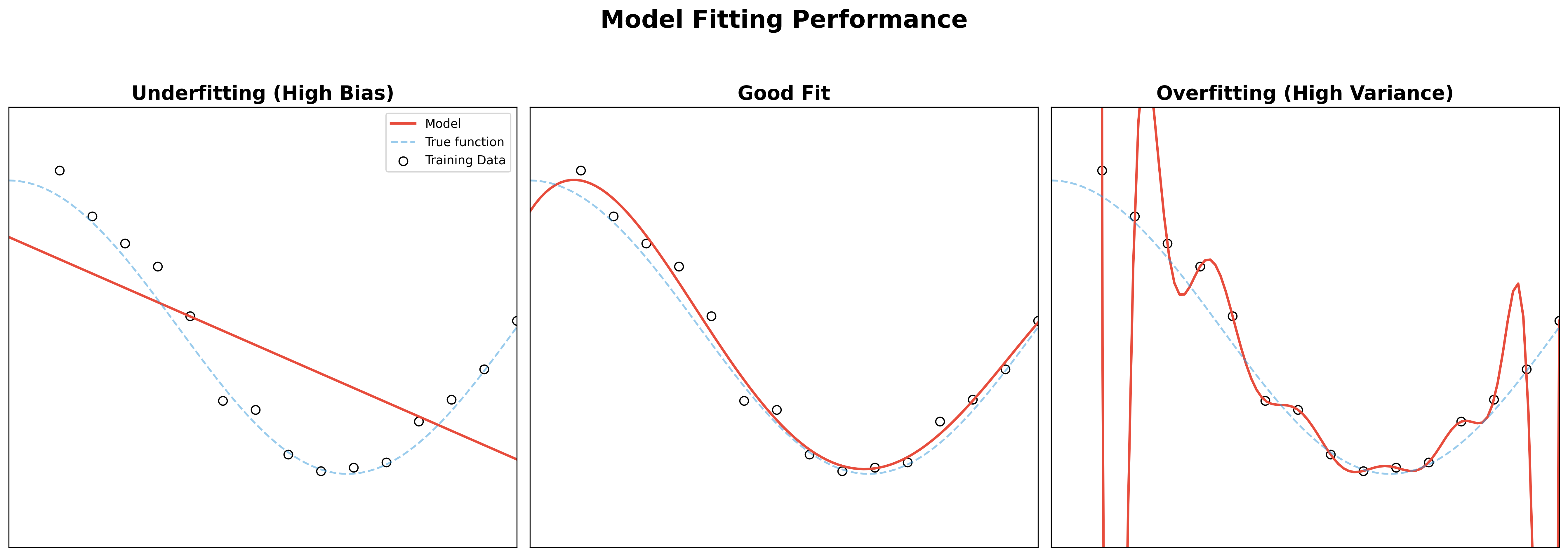
- Overfitting: The model performs very well on the training data but poorly on unseen evaluation data. This happens when the model learns the training data's noise and specific details rather than the underlying general pattern. Typically the model is too complex here.
- Underfitting: The model performs poorly on both the training and evaluation data. This happens when the model is too simple to capture the underlying relationship between the input features (X) and the target variable (Y). Typically the model is too simple (Input features are not expressive enough to derive the target well) or the model is created with little data.
Typical procedures to improve underfitting models:
- Add more data to the training set.
- Add new domain-specific features or change the types of feature processing used.
- Decrease the amount of regularization used.
Typical procedures to improve overfitting models:
- Consider using fewer feature combinations.
- Increase the amount of regularization used.
What is Regularization?
In very simple terms, regularization adds a penalty as model complexity increases, thereby decreasing the model's complexity. It works by discouraging the model from learning the noise in the training data, which helps prevent overfitting.
Common regularization techniques include:
- L1 (Lasso) and L2 (Ridge) Regularization: Adding penalty terms based on the magnitude of the weights.
- Dropout: Randomly disabling neurons during training (common in Deep Learning).
- Early Stopping: Monitoring validation performance and stopping training before overfitting occurs.
For detailed explanations, mathematical formulas, and implementation examples, see the dedicated Regularization chapter.
Difference between Bias and Variance in ML Models
Bias is the difference between the average prediction of our model and the correct value we are trying to predict. High bias indicates the model is too simple and is underfitting.
Variance is the variability of a model's prediction for a given data point. High variance indicates the model is too complex and is sensitive to the specific data it was trained on, meaning it is overfitting.