Hyperparameters
In machine learning, there are two types of parameters:
- Model Parameters: These are learned from the data during the training process. An example is the weights in a linear regression model.
- Hyperparameters: These are set before the training process begins. They are not learned from the data but are configurations that control how the learning algorithm works.
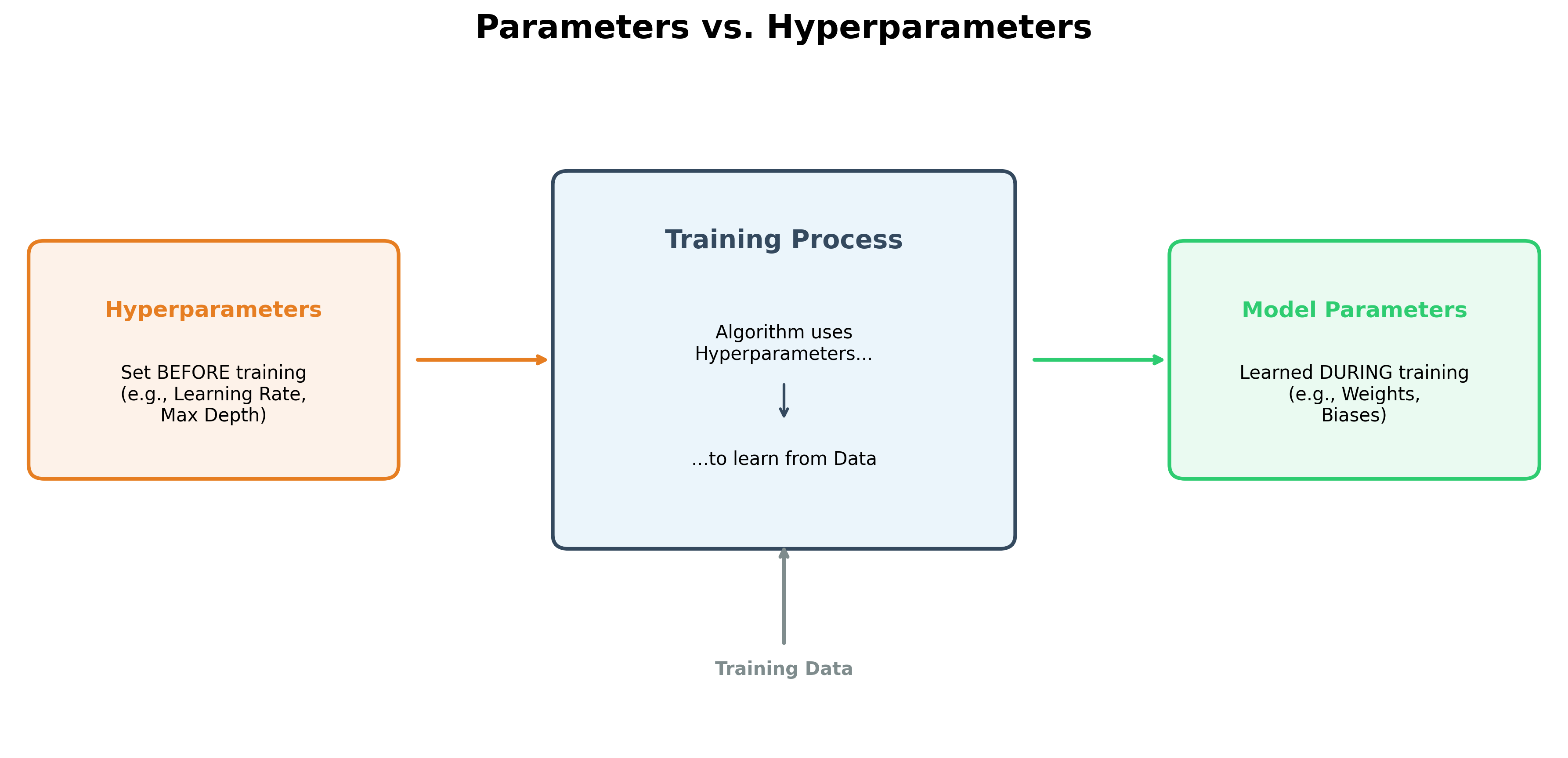
Hyperparameters can have a significant influence on the performance of the trained model. They control the trade-off between bias and variance, affecting how well the model generalizes to new data.
The Network-Human Interface
Think of hyperparameters as the knobs on a control panel. While the machine learns the internal weights, the human designer "tunes" these knobs to find the perfect configuration for the neural network to process data into accurate predictions.
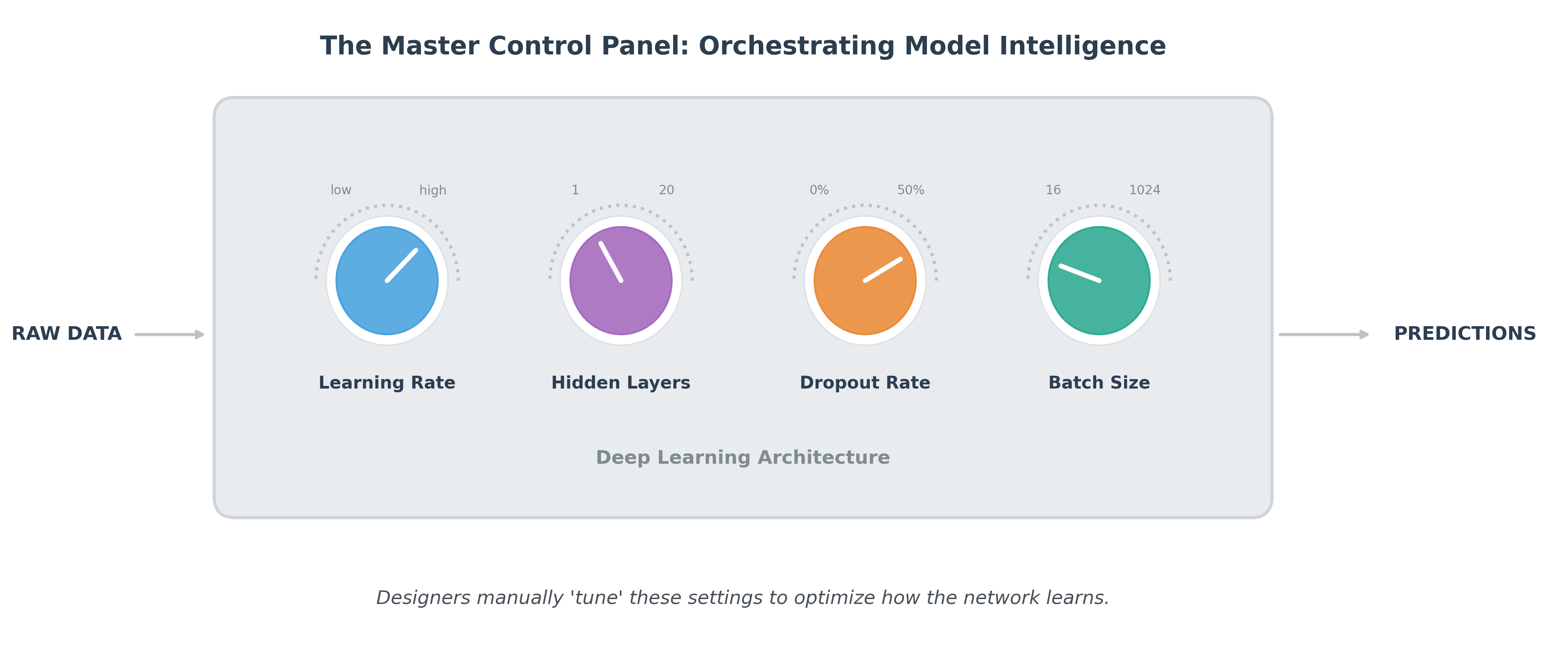
Finding the right set of hyperparameters is a crucial step in building a high-performing model. In scikit-learn, when you instantiate a model (e.g., DecisionTreeRegressor(max_depth=5)), the arguments you pass are the hyperparameters.
Here are some examples of common hyperparameters:
- The learning rate for training a neural network.
- The number of neighbors (k) in a K-Nearest Neighbors model.
- The maximum depth (
max_depth) for a decision tree. Keeping the depth low can reduce overfitting. - The minimum samples per leaf (
min_samples_leaf) in a decision tree. Increasing this value can also reduce overfitting.
Hyperparameter Tuning Methods
Manually testing different combinations of hyperparameters is tedious and inefficient. Scikit-learn provides automated methods to search for the optimal hyperparameter settings.
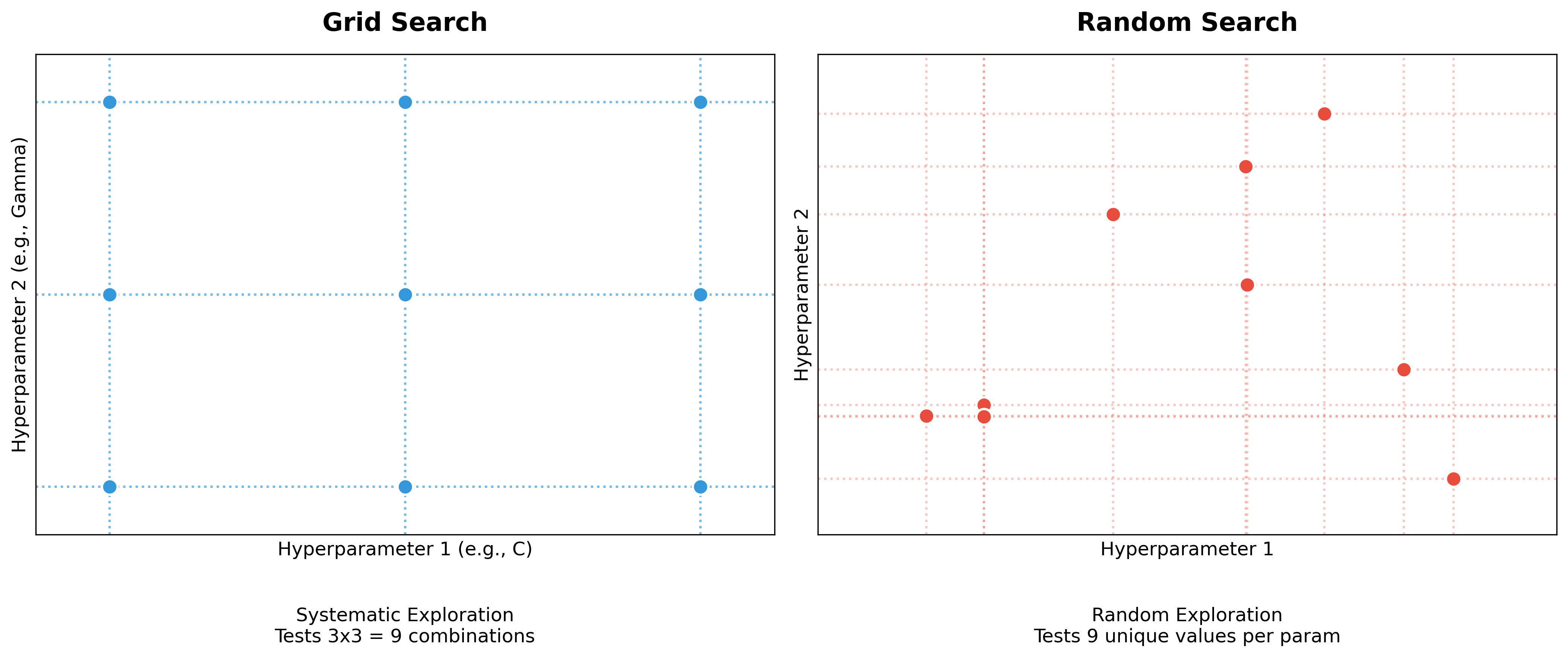
The two most popular are:
GridSearchCV
GridSearchCV performs an exhaustive search over a specified grid of hyperparameter values. It trains and evaluates a model for every possible combination of the hyperparameters you provide, using cross-validation to determine which combination performs the best.
Let's take an example of finding the optimal max_depth for a Decision Tree:
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeRegressor
# Assume X_train and y_train are already defined
# Define the grid of hyperparameters to search
params = {"max_depth": [None, 2, 4, 6, 8, 10, 12, 20]}
# Instantiate the regression model
reg = DecisionTreeRegressor(random_state=2)
# Create GridSearchCV with the model, params, scoring method, and cross-validation folds
grid_reg = GridSearchCV(reg, params, scoring="neg_mean_squared_error", cv=5, n_jobs=-1)
# Fit grid_reg on the training data
grid_reg.fit(X_train, y_train)
# Extract the best parameters found
best_params = grid_reg.best_params_
# Print the best hyperparameters
print("Best params:", best_params)
Output:
Best params: {'max_depth': 4}
You can define a grid with multiple hyperparameters to test all combinations:
params = {"max_depth": [4, 6, 8], "min_samples_leaf": [0.05, 0.1, 0.2]}
# GridSearchCV will now test all 3x3 = 9 combinations.
The Curse of Dimensionality: Be aware that the number of models to train grows exponentially with the number of hyperparameters and values in the grid. A large grid can take a very long time to run.
Once the search is complete, you can access the best score and the best model itself:
best_score = grid_reg.best_score_
best_model = grid_reg.best_estimator_
You can then use this best_model to make predictions on your test data:
y_pred = best_model.predict(X_test)
You can set other scoring algorithms as well. Here is the complete list of available options: https://scikit-learn.org/stable/modules/model_evaluation.html#common-cases-predefined-values
RandomizedSearchCV
When the search space is very large, GridSearchCV can be too slow. RandomizedSearchCV offers a more efficient alternative. Instead of trying every combination, it samples a fixed number of random combinations from the hyperparameter space, controlled by the n_iter parameter. This can often find a very good combination much faster than an exhaustive grid search.
Beyond Scikit-Learn: Intelligent Tuning with Google Vizier
While Grid and Random Search are powerful, they are often "blind" to the results of previous trials. Modern cloud-based tools like Google Vizier provide a more intelligent approach.
Google Vizier is a service for Black-Box Optimization. Instead of just guessing randomly, it uses advanced algorithms (like Bayesian Optimization) to:
- Learn from History: It analyzes the results of previous hyperparameter trials.
- Suggest Better Knobs: It intelligently picks the next set of hyperparameters that are most likely to improve the model's performance.
- Optimize Efficiently: It can find the "sweet spot" for your hyperparameters with significantly fewer trials than traditional methods, saving time and compute costs.
In modern ML workflows (like those on Google Cloud Vertex AI), Vizier acts as the automated "hand" that turns the knobs for you.