Encoding Categorical Values
Most machine learning models require all input and output variables to be numeric. This means that if your data contains categorical variables, you must encode them into numbers before you can fit and evaluate your model. This process of converting categorical variables into a numerical format is called encoding.
There are two techniques that are popularly used:
Ordinal Encoding - for Ordinal Data
This technique should be used when the categorical values have a natural, ordered relationship. For e.g., if the distinct values in the temperature column are 'hot', 'warm' and 'cold', then we can easily replace the categorical values with numerical values such as 3, 2, and 1 where the higher the number, the hotter the temperature.
The same logic holds good for a 'height' column that has 'short', 'medium' and 'tall'; another example is on the 'rating' column that has 'excellent', 'good', 'average' and 'bad' values.
Using OrdinalEncoding of SciKit
Using OrdinalEncoder of Scikit learn library, we can encode such columns easily as shown below:
import pandas as pd
from sklearn.preprocessing import OrdinalEncoder
df = pd.DataFrame(
{
"rating": ["Excellent", "Good", "Average", "Bad"],
"state": ["MI", "CA", "AA", "ZZ"],
"temp": ["cold", "warm", "hot", "hot"],
}
)
ordinalEncoder = OrdinalEncoder()
df[["encoded_rating", "encoded_temp"]] = ordinalEncoder.fit_transform(
df[["rating", "temp"]]
)
df.head()
Output:
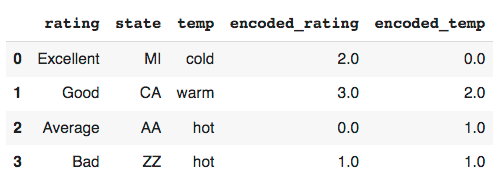
The two new columns are the dummy variables; encoded_rating and encoded_temp. Although the values were encoded, do you notice a problem? The encoder has assigned numbers based on the alphabetical order of the categories ('Average': 0, 'Bad': 1, 'Excellent': 2, 'Good': 3), not their inherent order. This is incorrect and will mislead the model.
To fix this, you must explicitly define the order of the categories by passing a list of lists to the categories parameter during instantiation. Here is the revised code and its output:
import pandas as pd
from sklearn.preprocessing import OrdinalEncoder
df = pd.DataFrame(
{
"rating": ["Excellent", "Good", "Average", "Bad"],
"state": ["MI", "CA", "AA", "ZZ"],
"temp": ["cold", "warm", "hot", "hot"],
}
)
ordinalEncoder = OrdinalEncoder(
categories=[["Bad", "Average", "Good", "Excellent"], ["cold", "warm", "hot"]]
)
df[["encoded_rating", "encoded_temp"]] = ordinalEncoder.fit_transform(
df[["rating", "temp"]]
)
df.head()
Output:
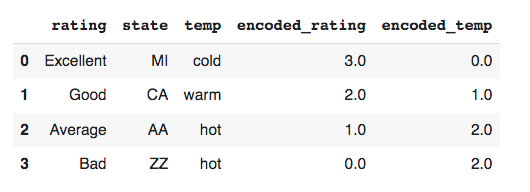
As can be seen from the example, OrdinalEncoder can be applied to multiple categorical columns at once.
Using LabelEncoding of SciKit
When to use LabelEncoder vs. OrdinalEncoder: LabelEncoder is designed for encoding the target variable (y) and only works on a single column at a time. OrdinalEncoder is designed for encoding features (X) and can work on multiple columns simultaneously. For encoding features, you should prefer OrdinalEncoder.
Here is an example of just converting the rating column with LabelEncoder:
from sklearn.preprocessing import LabelEncoder
import pandas as pd
labelEndoder = LabelEncoder()
df = pd.DataFrame(
{
"rating": ["Excellent", "Good", "Average", "Bad"],
"state": ["MI", "CA", "AA", "ZZ"],
"temp": ["cold", "warm", "hot", "hot"],
}
)
df["encoded_rating"] = labelEndoder.fit_transform(df.rating)
print(df)
Note that LabelEncoder does not have a parameter to specify the order of categories; it will always assign labels alphabetically. This is why it's generally not recommended for encoding ordinal features.
Applying LabelEncoder for the entire table
You can also apply LabelEncoder for the entire table using the 'apply' method of the dataframe. Here is an example:
from sklearn.preprocessing import LabelEncoder
import pandas as pd
labelEndoder = LabelEncoder()
df = pd.DataFrame(
{
"rating": ["Excellent", "Good", "Average", "Bad"],
"state": ["MI", "CA", "AA", "ZZ"],
"temp": ["cold", "warm", "hot", "hot"],
}
)
df2 = df.apply(labelEndoder.fit_transform)
df2
In the above example, all the columns will be applied with this encoder and the current categorical values will be replaced with numerical values from 0 to n-1 where 'n' is the number of unique categorial values of each column However, if any of the columns have mixed datatypes, like both string and number, then the above dataframe transfrom fails. Instead you can first convert all values to string and then apply the encoder.
df.astype(str)
Using OneHot Encoding
When the categorical variables do not have an ordered relationship (e.g., 'state': ['MI', 'CA', 'AA']), using ordinal encoding would incorrectly imply an order. For these nominal categorical variables, One-Hot Encoding is the appropriate technique.
This method creates a new binary column for each unique category. For each row, a '1' is placed in the column corresponding to its category, and '0's are placed in all other new columns.
Here is an example;
from sklearn.preprocessing import OneHotEncoder
import pandas as pd
onehotEncoder = OneHotEncoder(sparse=False)
df = pd.DataFrame(
{
"rating": ["Excellent", "Good", "Excellent", "Bad"],
"state": ["MI", "CA", "AA", "ZZ"],
"temp": ["cold", "warm", "hot", "hot"],
}
)
df[sorted(df["rating"].unique())] = onehotEncoder.fit_transform(df[["rating"]])
df
Output:
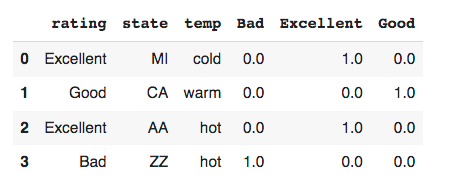
As you can see there are three new columns added; each column has the name of one unique value in the 'rating' column. Only one column will have a value of '1' and the rest of the columns are set to '0'. In this example, the new column names are also given the unique names of the categorical value to make things clear.
Using get_dummies() of pandas for OneHot Encoding
Instead of using sklearn's encoder, you can also use get_dummies method of pandas to get the same result as below
import pandas as pd
df = pd.DataFrame(
{
"rating": ["Excellent", "Good", "Excellent", "Bad"],
"state": ["MI", "CA", "AA", "ZZ"],
"temp": ["cold", "warm", "hot", "hot"],
}
)
pd.get_dummies(df[["rating"]])
Note on Multicollinearity: When you one-hot encode a variable, you create new columns that are perfectly correlated. For example, if you know a row is not 'Bad' and not 'Excellent', it must be 'Good'. This is called multicollinearity and can cause problems for some models (like linear regression). To avoid this, you can drop one of the new columns by setting drop_first=True. The information from the dropped column is implicitly captured in the remaining ones (if they are all '0', it implies the dropped category). pd.get_dummies(df[['rating']], drop_first=True)