Deep Learning
What is Deep Learning?
Deep Learning is a subfield of machine learning based on Artificial Neural Networks (ANNs). While traditional algorithms are powerful, they can struggle with highly complex, unstructured data like images, audio, and text. Deep learning excels at these tasks by using 'deep' networks with many layers to automatically learn intricate patterns and features directly from the data.
The Building Block: The Artificial Neuron
The fundamental building block of a neural network is the artificial neuron (or perceptron). Inspired by biological neurons, it is a mathematical function that processes information in several distinct steps.
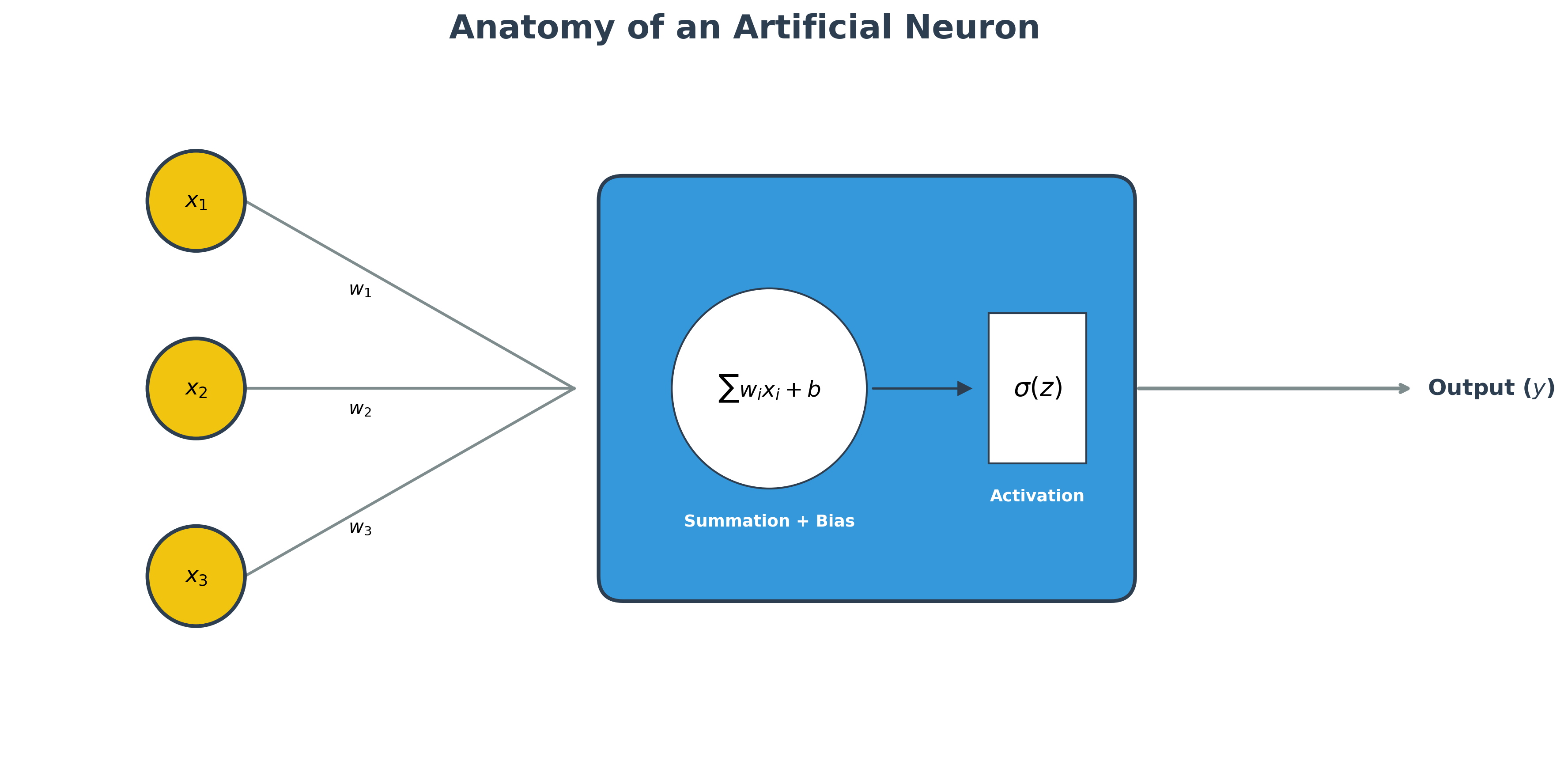
How it works (Step-by-Step):
- Receive Inputs (): The neuron receives raw data (like pixels or features).
- Apply Weights (): Each input is multiplied by a Weight. This determines how much "importance" or "influence" that specific input has on the final result.
- Summation (): The neuron sums up all the weighted inputs and adds a Bias (). Think of the bias as an "offset" that helps the neuron better fit the data patterns.
- Activation (): This sum is passed through an Activation Function. This is the most critical step—it introduces non-linearity, allowing the neuron to decide whether it should "fire" or not.
- Output (): The final result is sent forward to the next layer of the network.
Creating a Network: Layers and "Depth"
These artificial neurons are organized into layers. A typical network has:
- An Input Layer that receives the initial data.
- One or more Hidden Layers where the computation and learning happen.
- An Output Layer that produces the final prediction.
A "deep" neural network is simply one that has multiple hidden layers. This depth allows the network to learn a hierarchy of features, from simple patterns in the early layers to complex concepts in the deeper layers.
The Feed-Forward Process
This is the process of a neural network making a prediction. Data flows in one direction: from the input to the output.
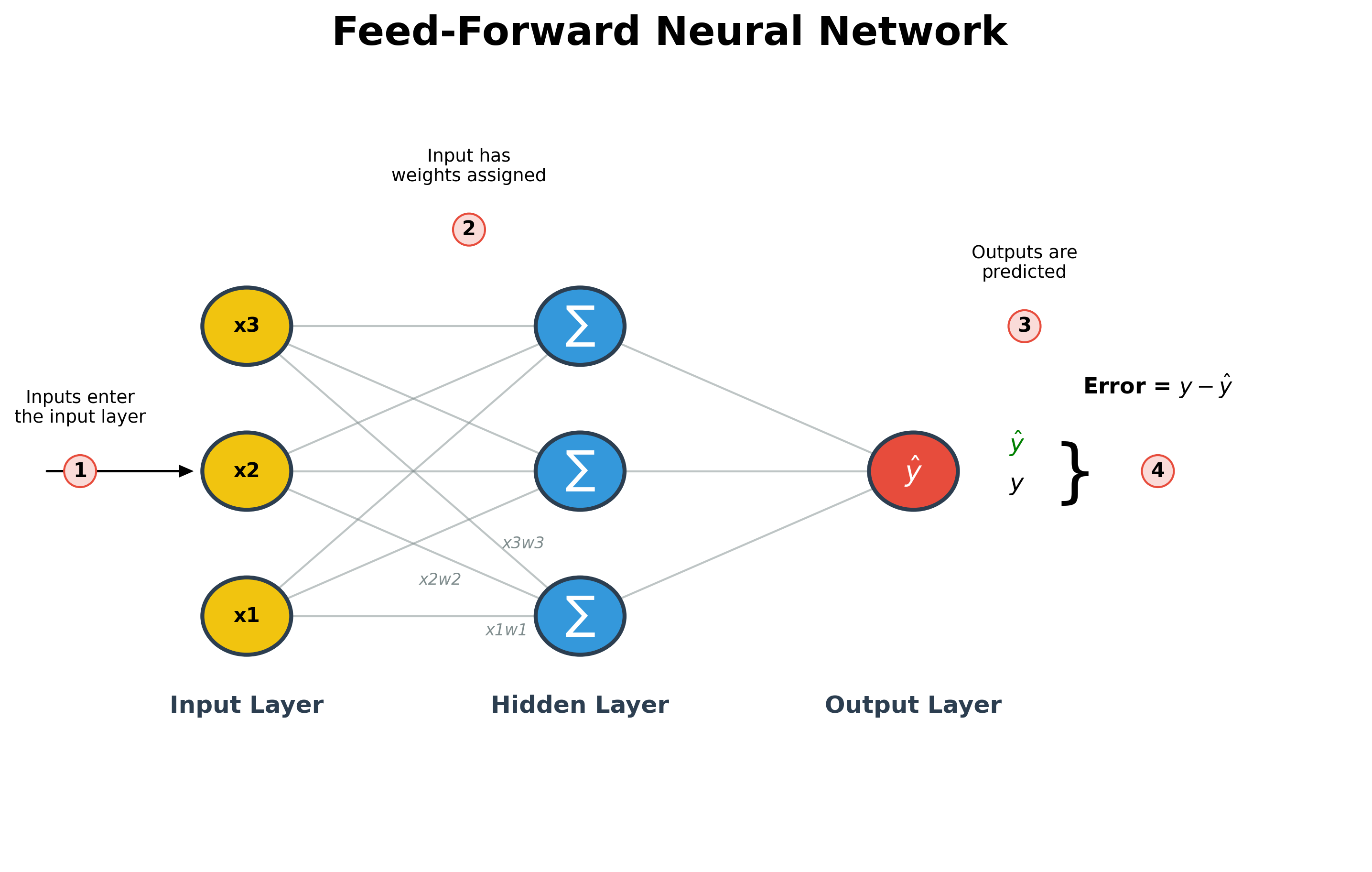
- Input: Raw data (like pixels of an image) enters the Input Layer.
- Weights & Computation: The data moves to the Hidden Layer, where each connection has a Weight (importance) assigned to it. The neurons sum these up and add a bias.
- Prediction: The final result is produced by the Output Layer as a predicted value ().
- Error Check: We compare the prediction () to the actual truth (). The difference between them is our Error.
How Neural Networks Learn: Backpropagation and Gradient Descent
A neural network learns by adjusting its weights and biases to minimize a cost function. This is achieved through an algorithm called Backpropagation, which works with Gradient Descent.
The Backpropagation Process
While Feed-Forward is about making a guess, Backpropagation is about learning from mistakes. It is the process of sending the error back through the network to update the weights.
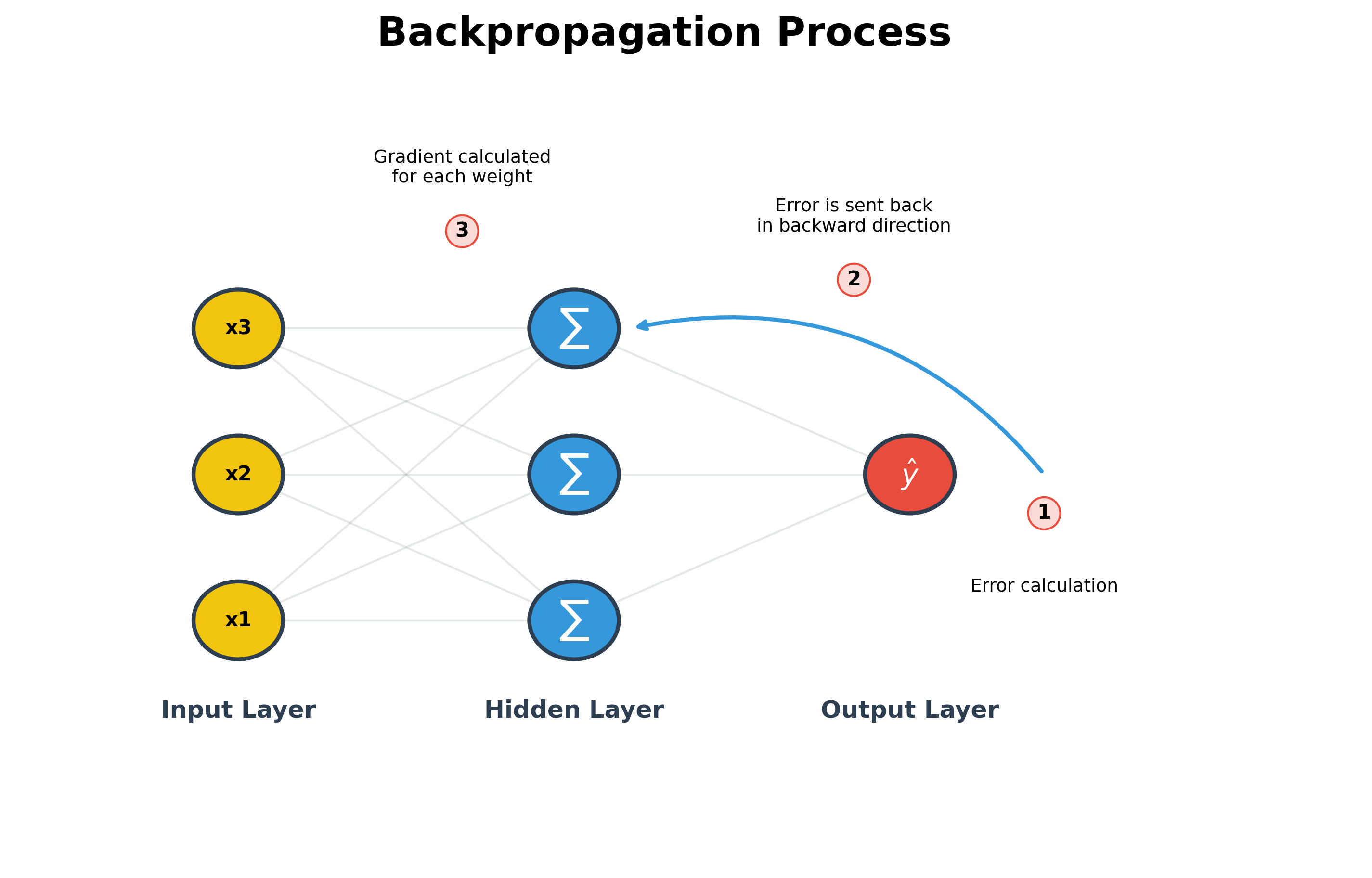
- Calculate Error: We start at the end by seeing how far off our prediction was.
- Reverse Flow: This error is sent backwards through the network, from the output layer to the hidden layers.
- Calculate Gradients: For every weight in the network, we calculate a Gradient. This is a mathematical value (using derivatives) that tells us exactly how much that specific weight was responsible for the error.
Once the gradients are known, Gradient Descent takes a small step to adjust those weights, and the whole cycle (Forward -> Backward) repeats until the model is accurate.
A Zoo of Architectures: Choosing the Right Tool for the Job
Different problems require different network designs. Here are some of the most common architectures:
Deep Neural Networks (DNNs): This is the standard, fully-connected network where each neuron in one layer is connected to every neuron in the next. They are a good general-purpose tool for structured data.
Convolutional Neural Networks (CNNs): For Images. CNNs are the go-to architecture for computer vision. They use special layers with 'filters' that slide across an image to detect patterns like edges, corners, textures, and eventually, complex objects.
Recurrent Neural Networks (RNNs): For Sequences. RNNs are designed for sequential data like text or time series. They have a 'memory' in the form of a hidden state that is passed from one time step to the next, allowing them to understand context and order.
Transformers: For Language. Transformers are a more modern architecture that has revolutionized Natural Language Processing (NLP). Their key innovation is the attention mechanism, which allows the model to dynamically weigh the importance of different words in the input sequence, leading to a much better understanding of context.
Popular Deep Learning Libraries
The two most dominant open-source libraries for deep learning are:
- TensorFlow: Developed by Google, it's a comprehensive ecosystem for building and deploying machine learning models. It includes the user-friendly Keras API.
- PyTorch: Developed by Facebook, it's known for its flexibility and Pythonic feel, making it very popular in the research community.