Batch Normalization
Training very deep neural networks can be challenging. One issue that arises is called Internal Covariate Shift. This refers to the phenomenon where the distribution of the inputs to a layer changes as the parameters of the preceding layers are updated during training. This instability can slow down the training process, making it harder for the optimizer to converge.
Batch Normalization (BatchNorm) is a technique designed to address this problem. It normalizes the inputs to a layer for each mini-batch, ensuring that the inputs have a stable distribution (mean of 0 and standard deviation of 1).
How Batch Normalization Works
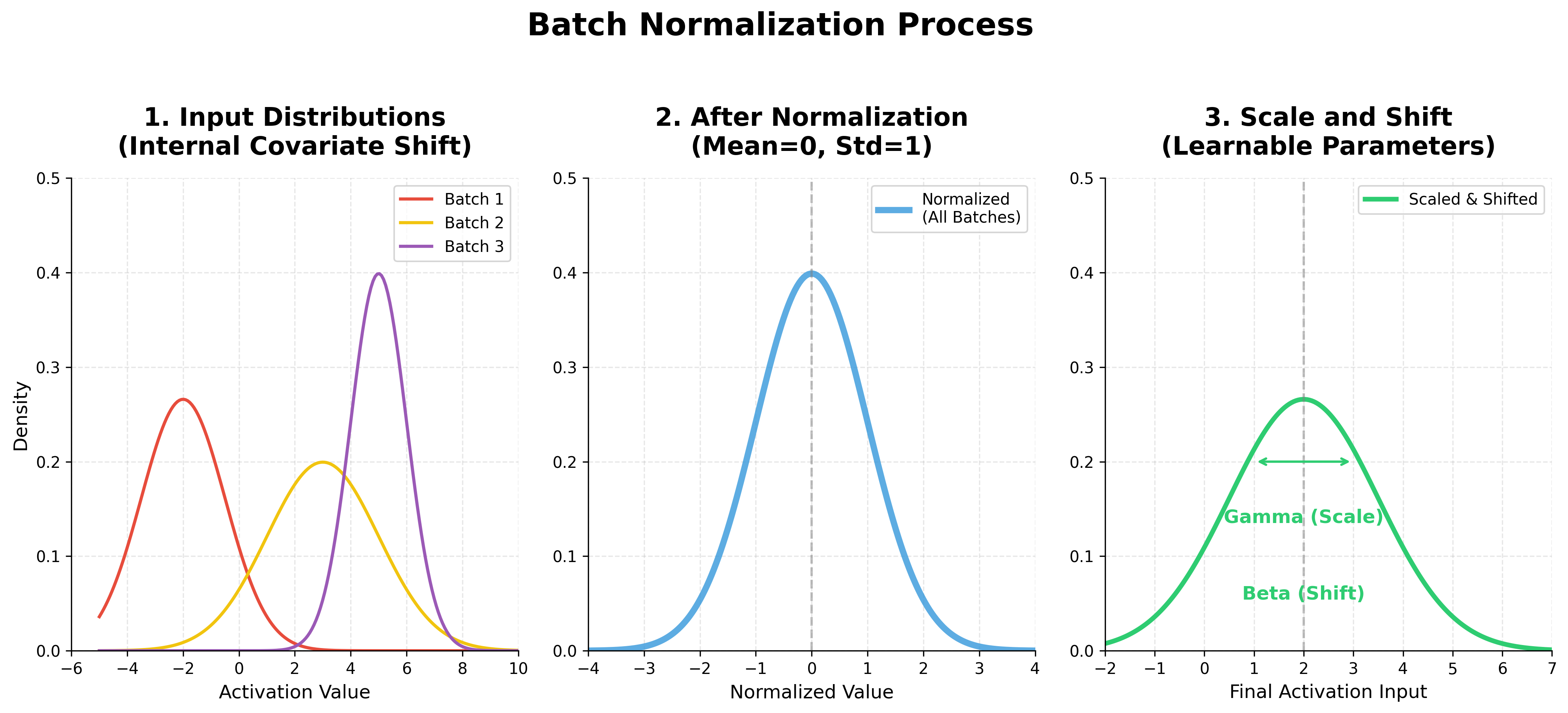
BatchNorm is typically inserted after a linear or convolutional layer but before the activation function. For each mini-batch, it performs two steps:
Normalize: It calculates the mean and standard deviation of the activations for the current mini-batch and uses them to normalize the activations.
normalized_activations = (activations - batch_mean) / (batch_std_dev + epsilon)The
epsilonis a small constant added for numerical stability to avoid division by zero.Scale and Shift: Normalizing the inputs might limit the expressive power of the layer. For example, a sigmoid activation function would be constrained to its linear region around zero. To overcome this, BatchNorm introduces two learnable parameters for each feature: a scale parameter (gamma, γ) and a shift parameter (beta, β).
output = gamma * normalized_activations + betaWhy do we need this? Simply normalizing inputs to have a mean of 0 and standard deviation of 1 can sometimes limit what the network can learn. For instance, if a Sigmoid activation function is used, inputs in this range (approx -1 to 1) fall into the linear part of the function, potentially causing the layer to lose its ability to model non-linear relationships.
The learnable parameters Gamma (γ) and Beta (β) give the network the flexibility to:
- Scale (γ): Expand or shrink the spread (standard deviation) of the data.
- Shift (β): Move the center (mean) of the data.
Ideally, the network learns the optimal scale and shift for each layer during training, effectively "undoing" the normalization if that provides better performance.
Benefits of Batch Normalization
- Faster Training: By stabilizing the input distributions, BatchNorm allows for the use of higher learning rates, which significantly speeds up convergence.
- Reduces Internal Covariate Shift: This is the primary motivation for the technique, leading to a more stable training process.
- Acts as a Regularizer: BatchNorm has a slight regularization effect. Because the mean and standard deviation are calculated on a mini-batch, it adds a small amount of noise to the network, which can help prevent overfitting. In some cases, it can even reduce the need for Dropout.
- Reduces Dependence on Initialization: It makes the network less sensitive to the initial weights.
Batch Normalization and Model Quality
According to Google Cloud's Guidelines for Model Quality, maintaining stable weight distributions is a hallmark of high-quality ML solutions. Batch Normalization is a primary tool used to achieve this stability.
Visualizing Stability
A key indicator of model health is the evolution of weight distributions over time. Without normalization, weights can drift significantly (Internal Covariate Shift), leading to vanishing or exploding gradients.
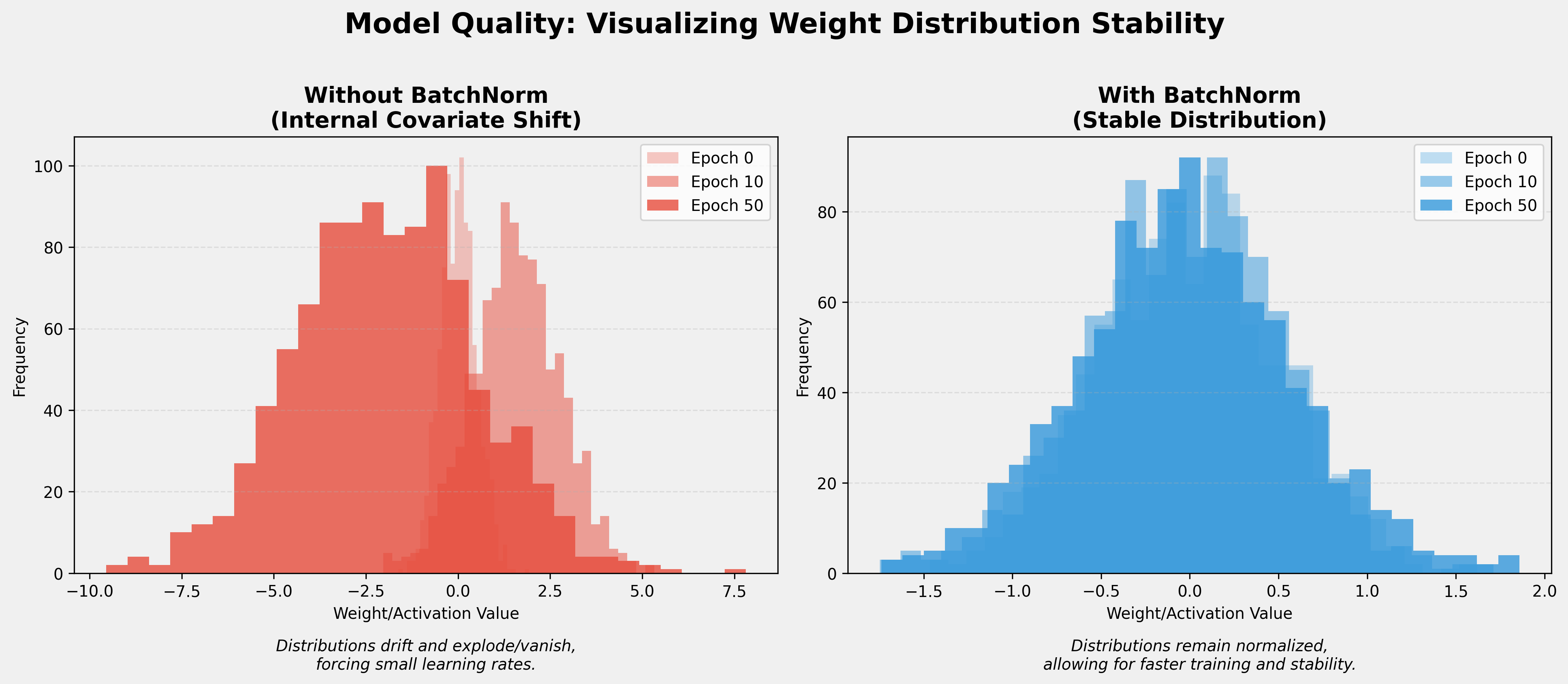
Quality Guidelines
- Monitor Weight Distributions: High-quality models avoid extreme shifts in weight values. BatchNorm keeps activations centered and scaled, which prevents the network from "saturating" (where gradients become near zero).
- Handle Vanishing/Exploding Gradients: By ensuring that inputs to activation functions (like Sigmoid or ReLU) stay within a healthy range, BatchNorm directly addresses the numerical instabilities that lead to
NaNloss values. - Faster Convergence: Stable distributions allow for higher learning rates. This means the model reaches its optimal quality faster and with less manual tuning of hyperparameters.
(Guidelines adapted from Google Cloud Architecture Framework: Model Quality.)
Batch Normalization in PyTorch
In PyTorch, you can easily add BatchNorm layers to your model using nn.BatchNorm1d for fully-connected layers or nn.BatchNorm2d for convolutional layers.
import torch.nn as nn
class ModelWithBatchNorm(nn.Module):
def __init__(self):
super().__init__()
self.linear1 = nn.Linear(784, 256)
self.bn1 = nn.BatchNorm1d(256) # The argument is the number of features
self.relu = nn.ReLU()
self.linear2 = nn.Linear(256, 10)
def forward(self, x):
x = self.linear1(x)
# Apply BatchNorm before the activation function
x = self.bn1(x)
x = self.relu(x)
x = self.linear2(x)
return x
Like Dropout, BatchNorm behaves differently during training and evaluation. During training, it uses the mean and standard deviation of the current mini-batch. During evaluation, it uses a running average of the mean and standard deviation calculated during training. It is therefore essential to call model.train() and model.eval() to switch between these modes.