Time and Space Complexity
In the previous lessons, you were introduced to different types of data structures: ordered collections, unordered collections, mutable and immutable structures, etc. But have you ever wondered about the advantages and disadvantages of choosing one structure over another for your application?
An algorithm's efficiency is measured by how few computer resources it consumes:
- Time Complexity: Refers to CPU usage (execution time).
- Space Complexity: Refers to RAM usage (memory consumption).
While other resources like network bandwidth may be relevant in specific contexts, computer science primarily focuses on time and space complexity.
Performance vs. Complexity
It is important to note the subtle difference between real-world performance and complexity measurements:
- Performance: The actual time or memory used when a program runs. This depends on both the code and the specific machine configuration (CPU speed, RAM type, etc.).
- Complexity: How the time and memory requirements of an algorithm scale as the input size grows. This is represented as a mathematical function of the input and is independent of the machine.
In this lesson, you will learn the time and space complexities of the algorithms that operate behind the scenes of these data structures.
Time Complexity
The time complexity of an algorithm refers to the amount of CPU time required for it to complete. This is calculated by totaling the time needed for the "basic operations" it performs, including arithmetic, assignments, comparisons, and read/write operations.
Let's look at a simple example: searching for an element in various data structures, starting with a list.
Analyzing Time Complexity of a List
To find a specific element in a list, you must iterate from the first position until the element is found. Once found, the iteration stops. The number of steps required depends on the element's position.
def is_element_present(target, my_list):
for element in my_list:
if target == element:
return True
return False
list_1 = ["a", "z", "d", 5, "e", "f", "i"]
print(is_element_present("f", list_1))
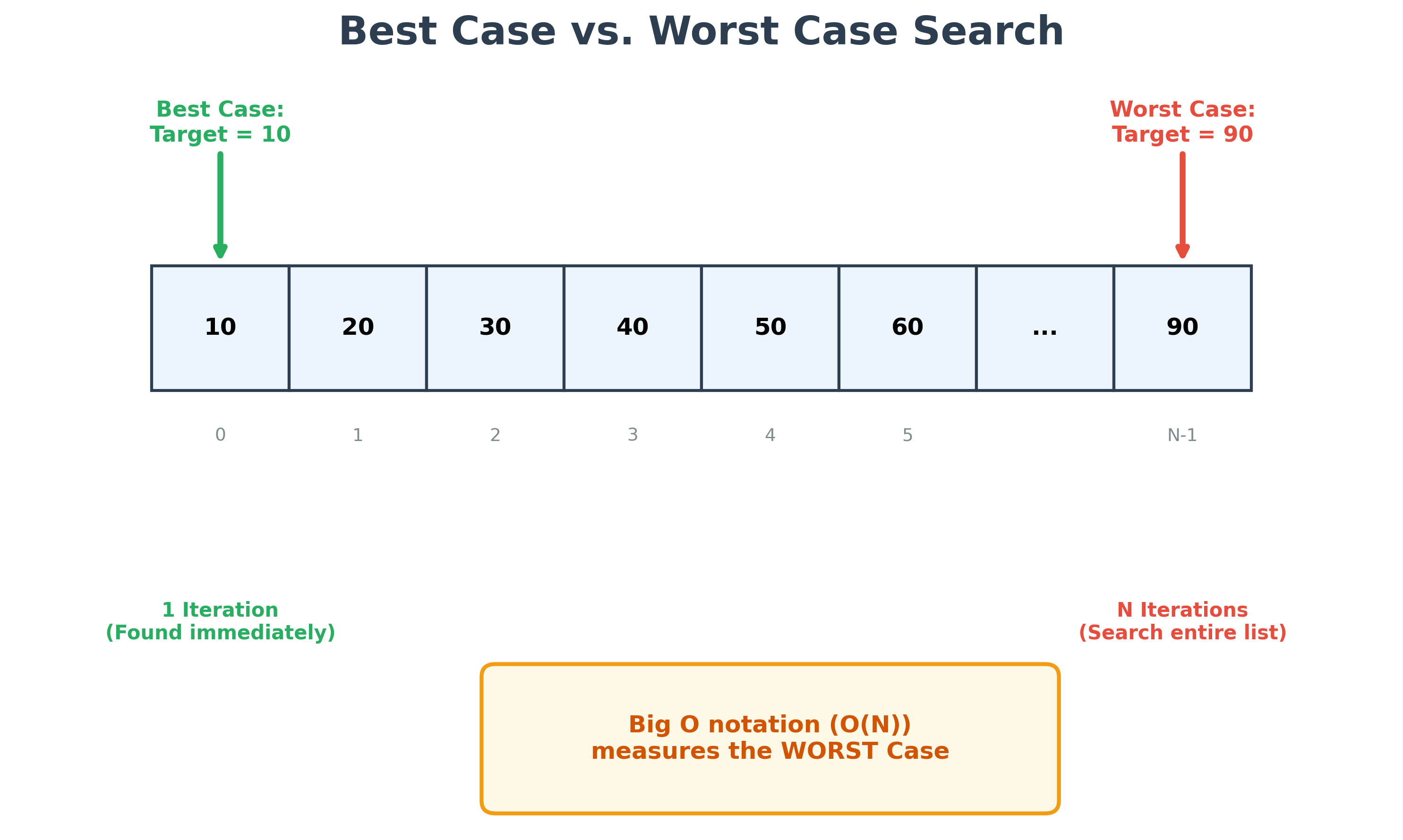
In the algorithm above:
- The best-case scenario is 1 iteration (if the element is at index 0).
- The worst-case scenario is N iterations (if the element is at the end of a list containing N elements).
Why Big O Uses the Worst Case?
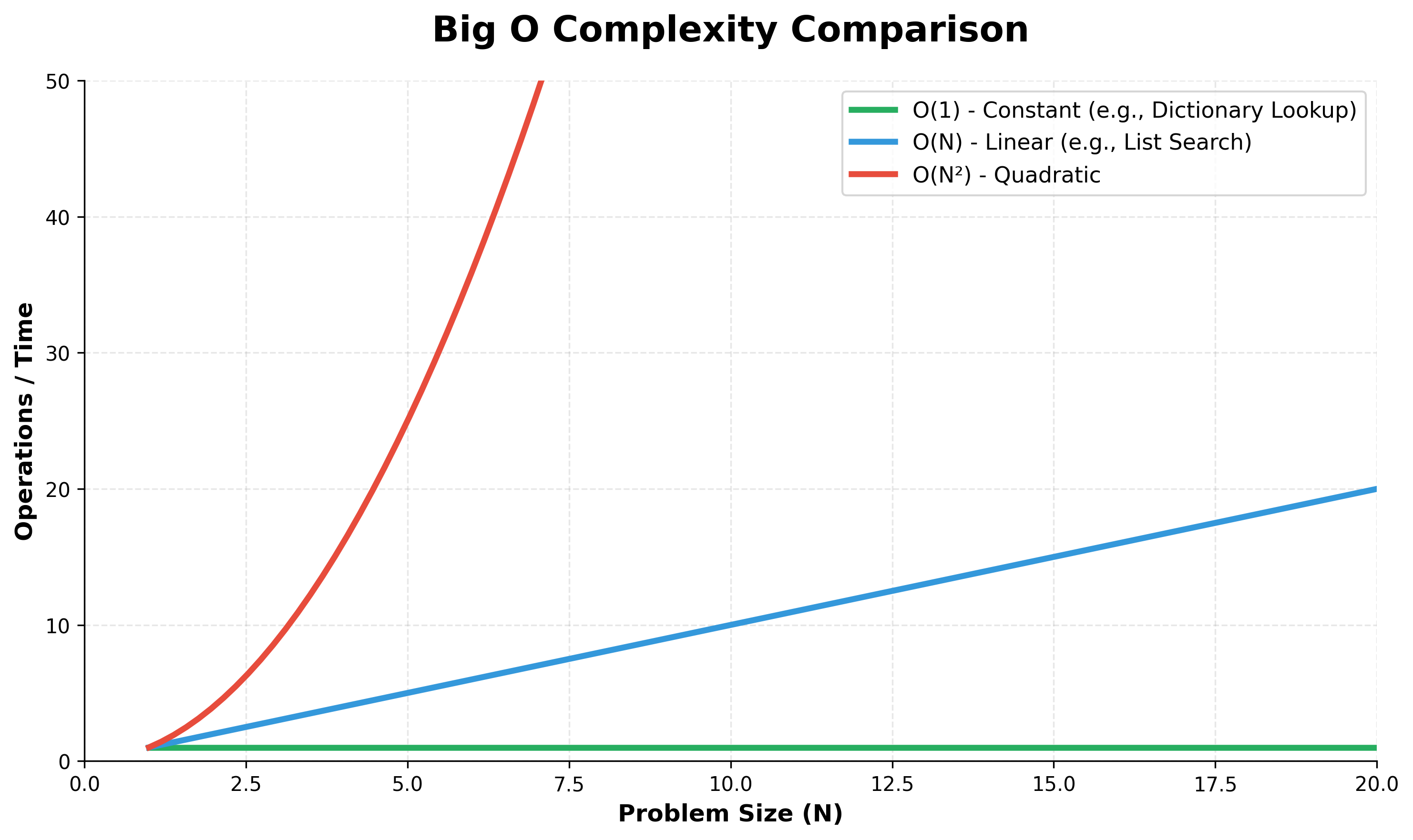
When measuring algorithmic complexity, we typically focus on the worst-case scenario. This provides an "upper bound" guarantee. If we know an algorithm is , we know that even in the most unlucky scenario, the time taken will not exceed a linear relationship with the input size.
While CPU time is used for comparisons and other logic, we are not usually interested in the exact number of operations. Instead, we focus on the relationship (the function) between the number of operations and the problem size (N).
In computer science, we represent this worst-case scenario using Big O notation. For the list search performed above, the Big O representation is:
This means that searching for an element in a list is a linear function of N. If the list is small, the search is fast; if the list is extremely large, the time required increases proportionally to the size of the list.
This linear search time complexity also applies to Tuples and Strings (all sequences). But what about a Set or a Dictionary?
Analyzing Time Complexity of a Dictionary
A dictionary is not a sequence. You retrieve a value by looking up its key. Internally, it uses a hash function to compute a "hash code," which allows it to jump directly to the key's location in memory.
Because a key lookup only takes the time required to compute that hash value, it occurs in constant time. It doesn't matter how large the dictionary is; you can access your key almost instantly.
Hence, the key lookup time complexity of a dictionary is:
This means the worst-case scenario for a lookup is independent of the number of items in the collection. This is also true for a Set, as both are unordered collections built using hash functions.
Quadratic Complexity O(N^2)
When you have a loop inside another loop (nested loops), the complexity often becomes quadratic. This typically happens when you need to compare every element in a list with every other element.
Example: Checking for duplicates by comparing pairs.
def has_duplicates(elements):
for i in range(len(elements)):
for j in range(len(elements)):
if i != j and elements[i] == elements[j]:
return True
return False
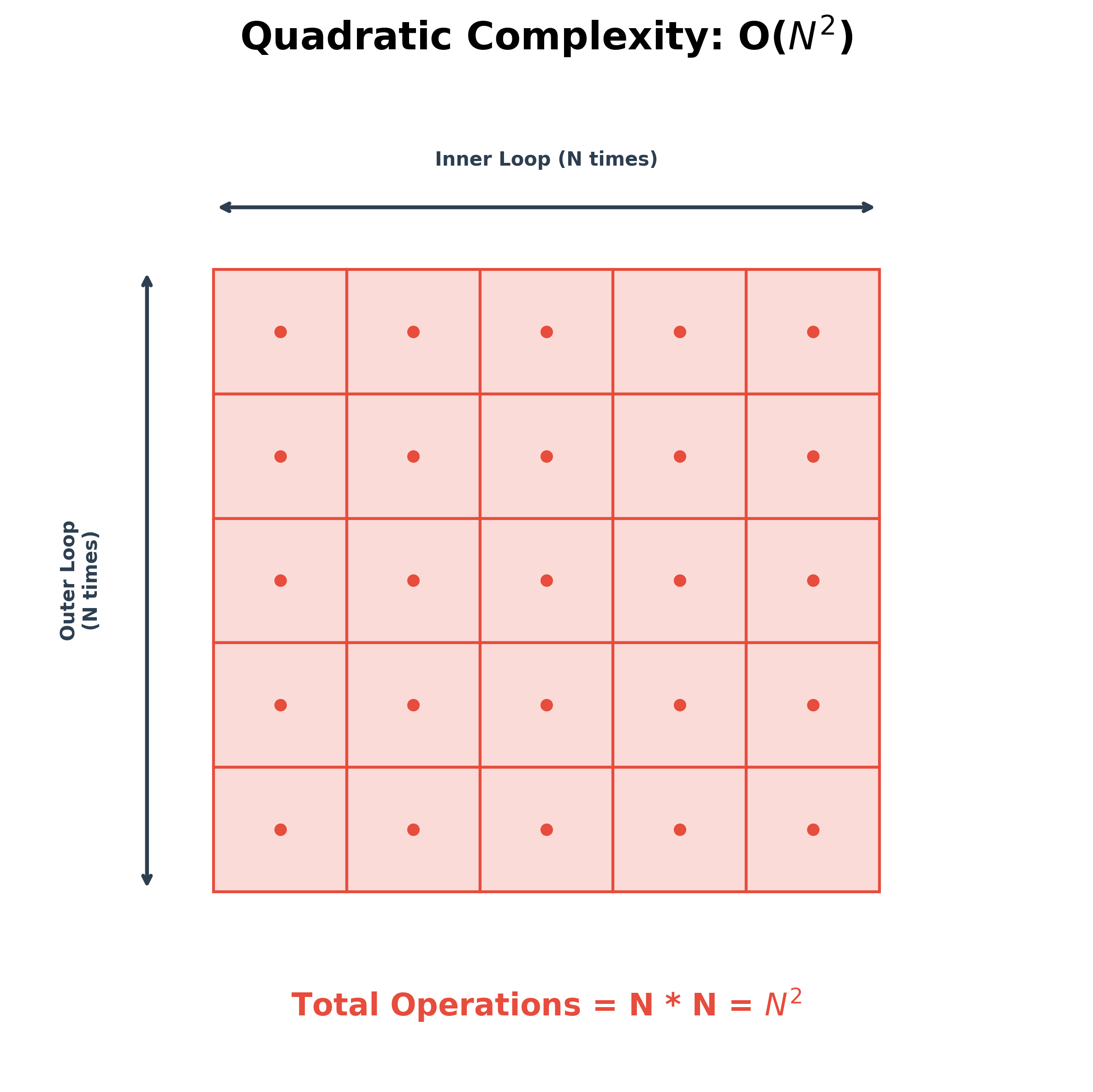
If the list has N elements, the outer loop runs N times. For each of those, the inner loop also runs N times.
Total operations:
If you double the input (2N), the time taken quadruples ()!
Summary
While we focused on lookups and searches, every operation—including insertion and deletion—is calculated similarly and represented using Big O notation.
In this lesson, you learned about time complexity. You can also compute space complexity by measuring how much RAM an algorithm consumes. We encourage you to research and explore space complexity further as an exercise.
Hands-on Exercises
Exercise 1: Scaling Math Audit
Assume you have a data deduplication algorithm. When processing a dataset of size :
- A linear time version of the algorithm completes in
1.5 seconds. - A quadratic time version of the algorithm also completes in
1.5 secondson this small sample.
Calculate how long both versions will take if the dataset grows to (a 10-fold increase):
- Compute the time for the version.
- Compute the time for the version.
# Write your calculations / code in the Python editor to verify math if needed
Click to view Answer
# 1. For O(N) linear complexity:
# If size increases by 10x, steps and time increase by 10x.
# 1.5 seconds * 10 = 15 seconds!
# 2. For O(N^2) quadratic complexity:
# If size increases by 10x, steps and time increase by 10^2 = 100x.
# 1.5 seconds * 100 = 150 seconds (2.5 minutes)!
Exercise 2: Analyze Optimized Code
Look at the Python function below that checks if a list contains duplicates:
def check_duplicate(items):
seen = set()
for item in items:
if item in seen:
return True
seen.add(item)
return False
- Explain the time complexity of lookup
item in seeninside a set. - Deduce the total worst-case time complexity of the entire
check_duplicatefunction. Choose between , , or .
# Write your thoughts / tests below
Click to view Answer
# 1. A lookup in a set ('item in seen') takes constant time: O(1).
# 2. The loop runs at most N times (for a list of N items).
# 3. Inside the loop, it performs O(1) operations (set lookup and set add).
# Therefore, the total worst-case complexity is O(N) (Linear Time).
# This is a huge optimization over the nested loop version which takes O(N^2)!