Boosting and XGBoost
In the previous chapter, we learned about Random Forests, which use an ensemble technique called Bagging. The core idea of Bagging is to build many independent models (trees) in parallel and average their predictions.
Boosting is another powerful ensemble technique, but it works differently. Instead of building models in parallel, Boosting builds them sequentially, where each new model tries to correct the errors made by the previous one. It's like a team of students where each student learns from the mistakes of the one before them.
Gradient Boosting Explained
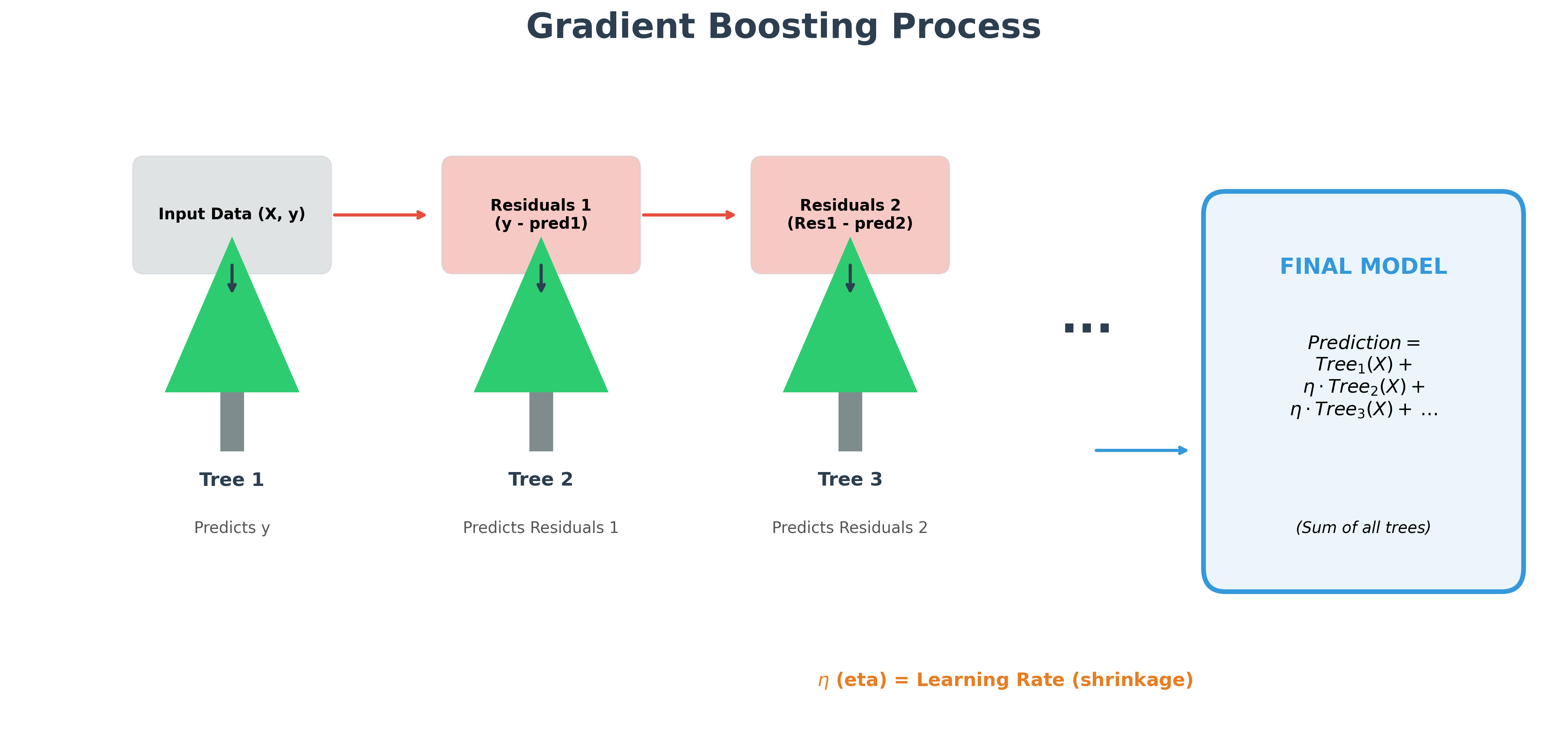
The most common type of boosting is Gradient Boosting. Here’s how it works with decision trees:
- Start with a single, simple tree: It makes an initial set of predictions for your data. These predictions will likely be mediocre.
- Calculate the errors: For each data point, we calculate the error (also called the residual):
error = actual_value - predicted_value. - Build a new tree to predict the errors: The next tree doesn't try to predict the original target
y. Instead, it's trained to predict the errors from the previous step. - Combine the predictions: To make a new, improved prediction, you add the prediction from the first tree and the prediction from the second (error-predicting) tree. This new combined prediction will be closer to the actual value.
- Repeat: You continue this process, adding new trees that sequentially predict the remaining errors. Each new tree makes the overall model a little bit better.
The final prediction is the sum of the predictions from all the trees in the sequence. This iterative error correction is what makes boosting so powerful.
XGBoost (eXtreme Gradient Boosting)
XGBoost is a specific implementation of the Gradient Boosting algorithm that has been engineered for extreme speed and performance. It became famous in the machine learning community for its regular success in Kaggle competitions, especially on structured or tabular data.
What makes XGBoost 'eXtreme'?
- Regularization: It has built-in L1 (Lasso) and L2 (Ridge) regularization, which helps prevent overfitting—a common problem with standard Gradient Boosting.
- Speed and Parallelization: It's designed to be computationally efficient and can take advantage of multi-core processors for faster training.
- Handling Missing Values: It has a clever built-in routine to handle missing data automatically.
- Flexibility: It offers a wide range of hyperparameters, giving data scientists fine-grained control over the model.
Because of its performance and accuracy, XGBoost is often a go-to algorithm for classification and regression tasks on tabular data.
This module is already part of Colab. On your local environment, you can install it using Conda:
conda install -c conda-forge xgboost
Reference:
- Original paper: https://arxiv.org/pdf/1603.02754.pdf
- Tutorial: https://xgboost.readthedocs.io/en/latest/tutorials/model.html