Decision Trees and Random Forests
Decision Trees and Random Forests are two popular and related machine learning algorithms. They are powerful tools for making predictions based on a series of decisions.
Decision Trees
A Decision Tree is a simple yet powerful algorithm that works like a flowchart of questions. It splits the data into smaller and smaller subsets based on feature values, learning decision rules to predict a target variable. Because it can be used for both categorical (Classification) and numerical (Regression) targets, it's often called CART (Classification and Regression Trees).
How a Tree Makes a Split: Gini Impurity
How does a tree decide which question to ask at each node? It chooses the split that results in the "purest" child nodes. Gini Impurity is a common metric used to measure this purity.
- A Gini score of 0 represents a perfectly pure node (all data points belong to a single class).
- A Gini score of 0.5 represents a completely impure node (data points are evenly distributed among classes).
The algorithm searches for the feature and split value that results in the lowest weighted average Gini score for the child nodes, effectively creating the most informative split.
Let's look at a simple tree for the Titanic dataset that splits only on the 'sex' of the passenger.
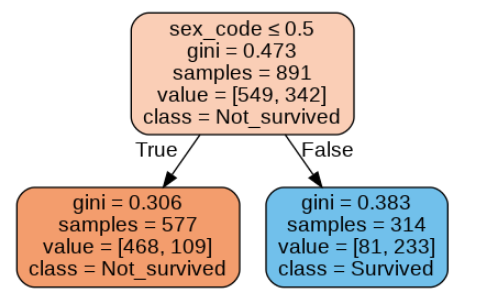
As we add more features, the tree grows, creating a more complex set of rules.
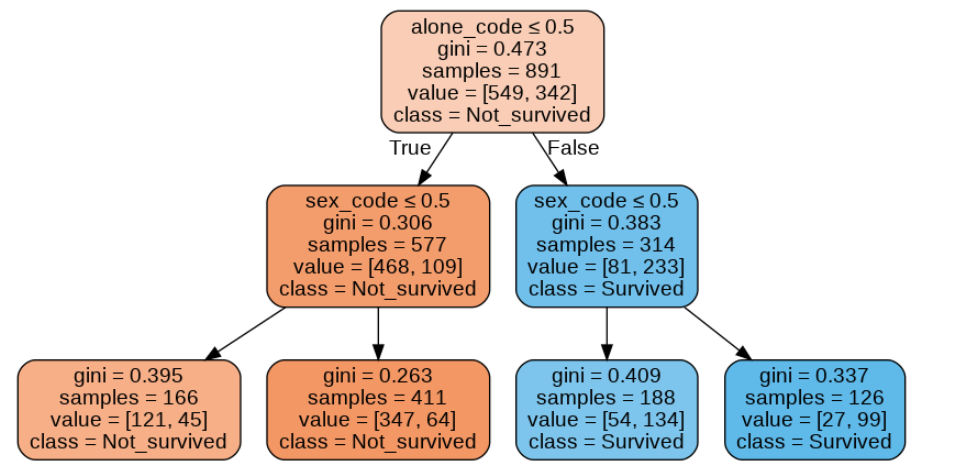
The Problem with Single Decision Trees
While individual decision trees are easy to interpret, they have a major weakness: they are prone to overfitting. A single tree can grow very deep and learn the intricate details and noise of the training data so well that it fails to generalize to new, unseen data.
The Solution: Ensemble Learning
The solution to the overfitting problem of single trees is Ensemble Learning—the idea that combining many weak models can create one strong model. Random Forest uses a specific ensemble method called Bootstrap Aggregating (Bagging).
Random Forest: An Ensemble of Trees
A Random Forest is an ensemble of many decision trees. It builds a 'forest' of trees and merges their predictions to get a more accurate and stable result. It combats the overfitting problem of single trees by introducing two key sources of randomness:
- Random Data Samples (Bootstrap): Each tree in the forest is trained on a different random sample of the original data (with replacement). This is the "Bagging" part.
- Random Feature Subsets: At each split in a tree, the algorithm only considers a random subset of the available features to find the best split.
This randomness ensures that the individual trees are different from each other and focus on different aspects of the data. The final prediction is made by averaging the predictions of all trees (for regression) or by taking a majority vote (for classification). This process reduces variance and makes the model much more robust.
Feature Importance
A great feature of Random Forest is the ability to calculate the importance of each feature. The model calculates how much each feature contributes to reducing impurity across all the trees in the forest. This is a very useful tool for feature selection.
Key Hyperparameters for Random Forest
n_estimators: The number of trees in the forest. More trees are generally better but increase computation time.max_features: The number of features to consider at each split.max_depth: The maximum depth of each individual tree.oob_score: (Out-of-Bag Score) A useful feature. If set toTrue, the model uses the data points left out of the bootstrap sample for a particular tree to get an unbiased estimate of its performance, similar to a validation set.
Splitting Criteria: Gini vs. Entropy
While Gini Impurity is the default criterion for splitting in scikit-learn, another option is Entropy. Entropy is a measure of uncertainty or randomness in the data. The goal is to choose splits that decrease entropy (i.e., increase information gain). In practice, Gini and Entropy often produce very similar results.