Naive Bayes Classifier
The Naive Bayes classifier is a simple but surprisingly powerful probabilistic algorithm. The core idea is to use the probabilities of features to predict the class of a given data point. It's particularly famous for its use in text classification tasks like spam filtering and sentiment analysis.
The algorithm is based on Bayes' Theorem, which calculates the probability of an event based on prior knowledge of conditions that might be related to the event.

The "Naive" Assumption: The Key to its Simplicity
The 'naive' part of the name comes from the algorithm's core assumption: it assumes that all the features are independent of each other, given the class.
For example, in a spam filter, it assumes the probability of the word 'won' appearing is completely independent of the probability of the word 'lottery' appearing within the same email. In reality, these words often appear together, so this assumption is not strictly true (it's 'naive').
However, this simplification is what makes the algorithm so fast and efficient. It allows us to calculate the total probability by simply multiplying the individual probabilities of each feature, and it works remarkably well in practice despite the flawed assumption.
How Naive Bayes Works: A Spam Filter Example
Let's see how it works with a spam filter. The goal is to calculate the probability that an email is spam, given the words in it: P(Spam | words).
1. Training Phase (Learning Probabilities): First, we 'train' the model by looking at a large dataset of labeled emails. We calculate:
- Prior Probabilities: The overall probability of any given email being spam or not spam. E.g.,
P(Spam) = 20%,P(Not Spam) = 80%. - Likelihoods: The probability of each word appearing, given that an email is spam or not spam. E.g.,
P('won' | Spam) = 5%,P('won' | Not Spam) = 0.01%.
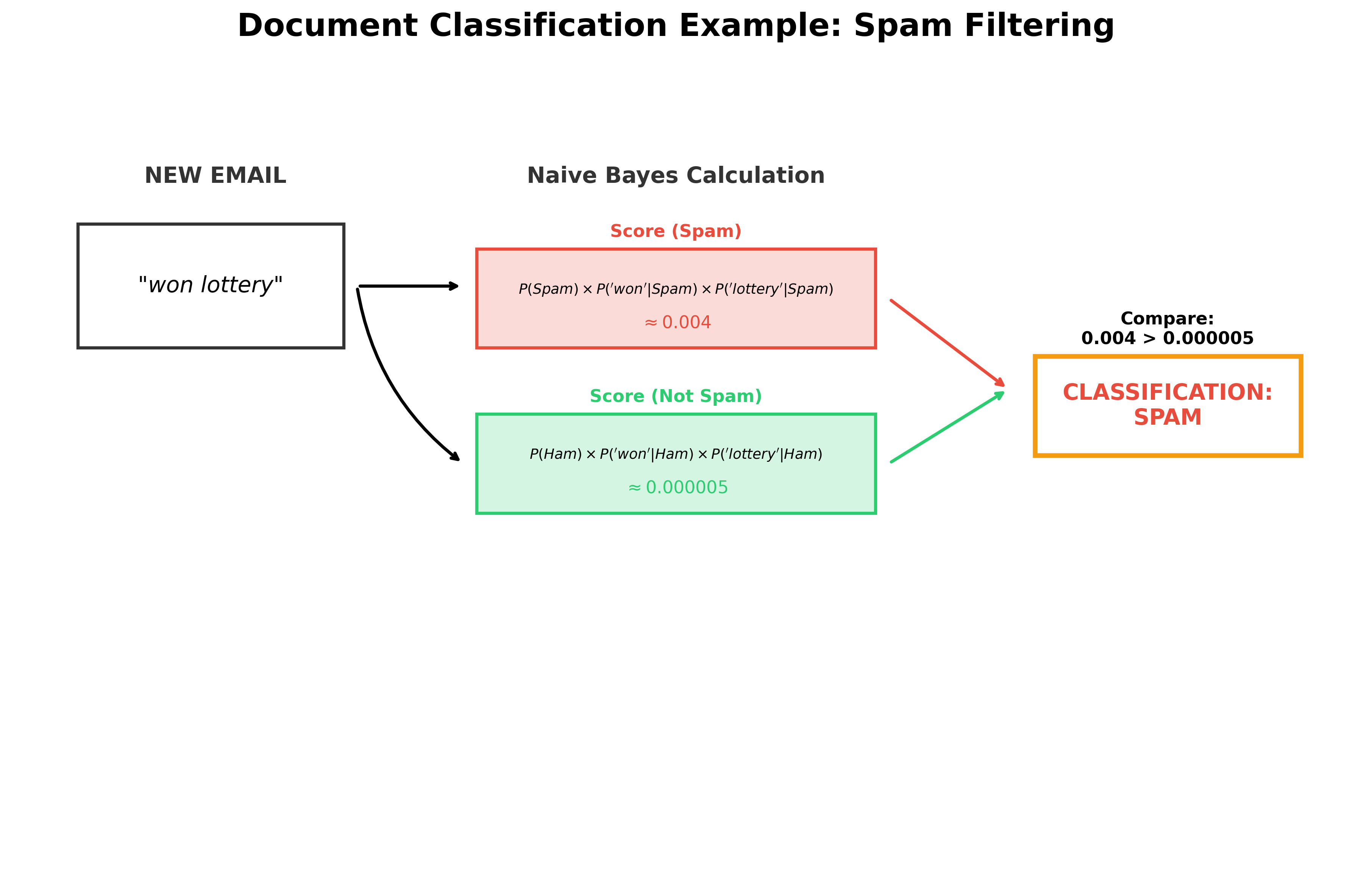
2. Prediction Phase (Applying Bayes' Theorem): Now, a new email arrives with the words "won lottery". To classify it, we calculate a score for each class by multiplying the prior by the likelihoods of each word:
Score(Spam) = P(Spam) * P('won' | Spam) * P('lottery' | Spam)Score(Not Spam) = P(Not Spam) * P('won' | Not Spam) * P('lottery' | Not Spam)
The algorithm then classifies the email as 'Spam' if Score(Spam) is higher, and 'Not Spam' otherwise.
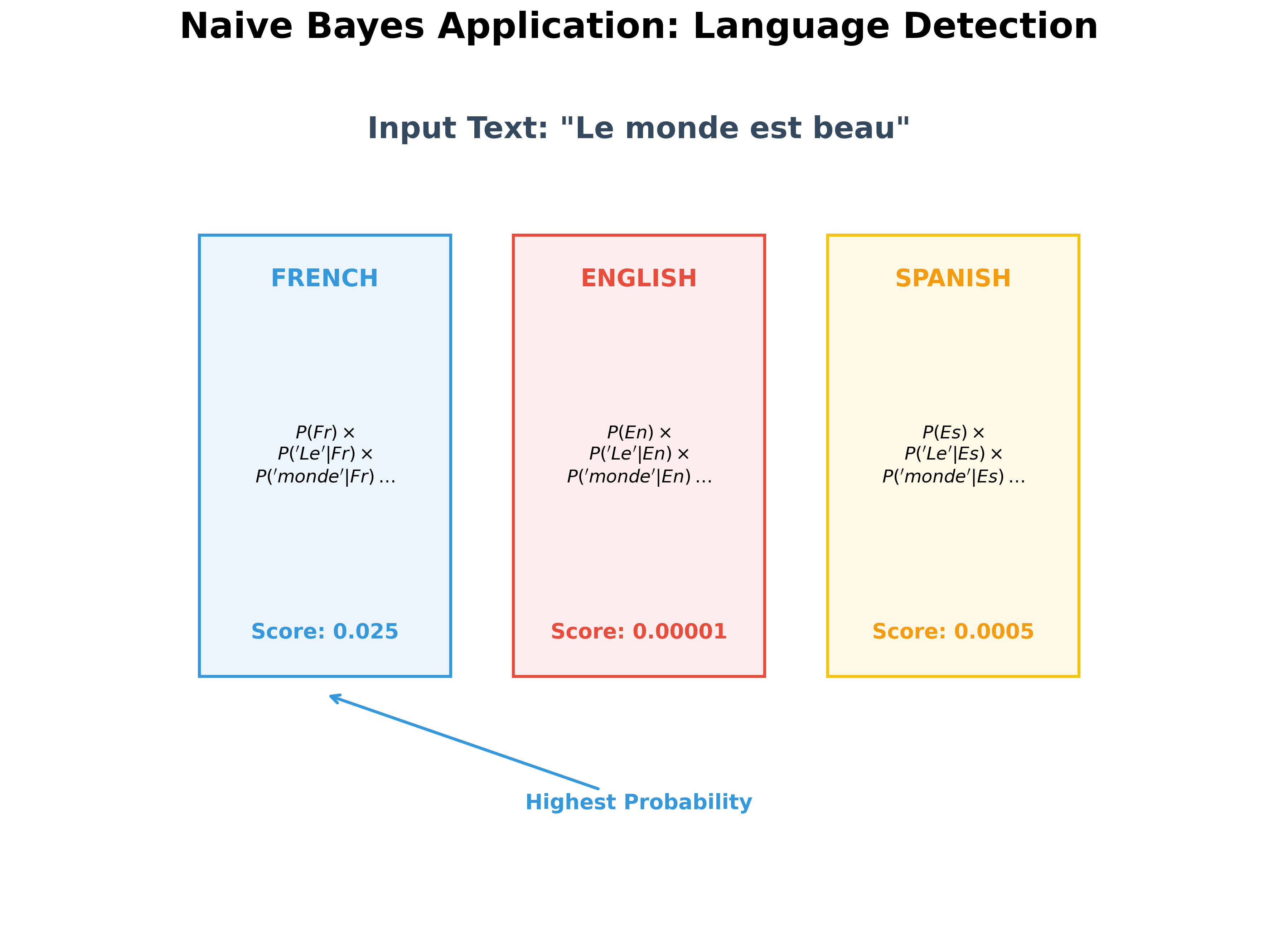
Another Example: Language Detection
Naive Bayes is also excellent for identifying the language of a document. By calculating the probability of words like "le", "la", "the", "el" appearing in different languages, the model can quickly classify a text string.
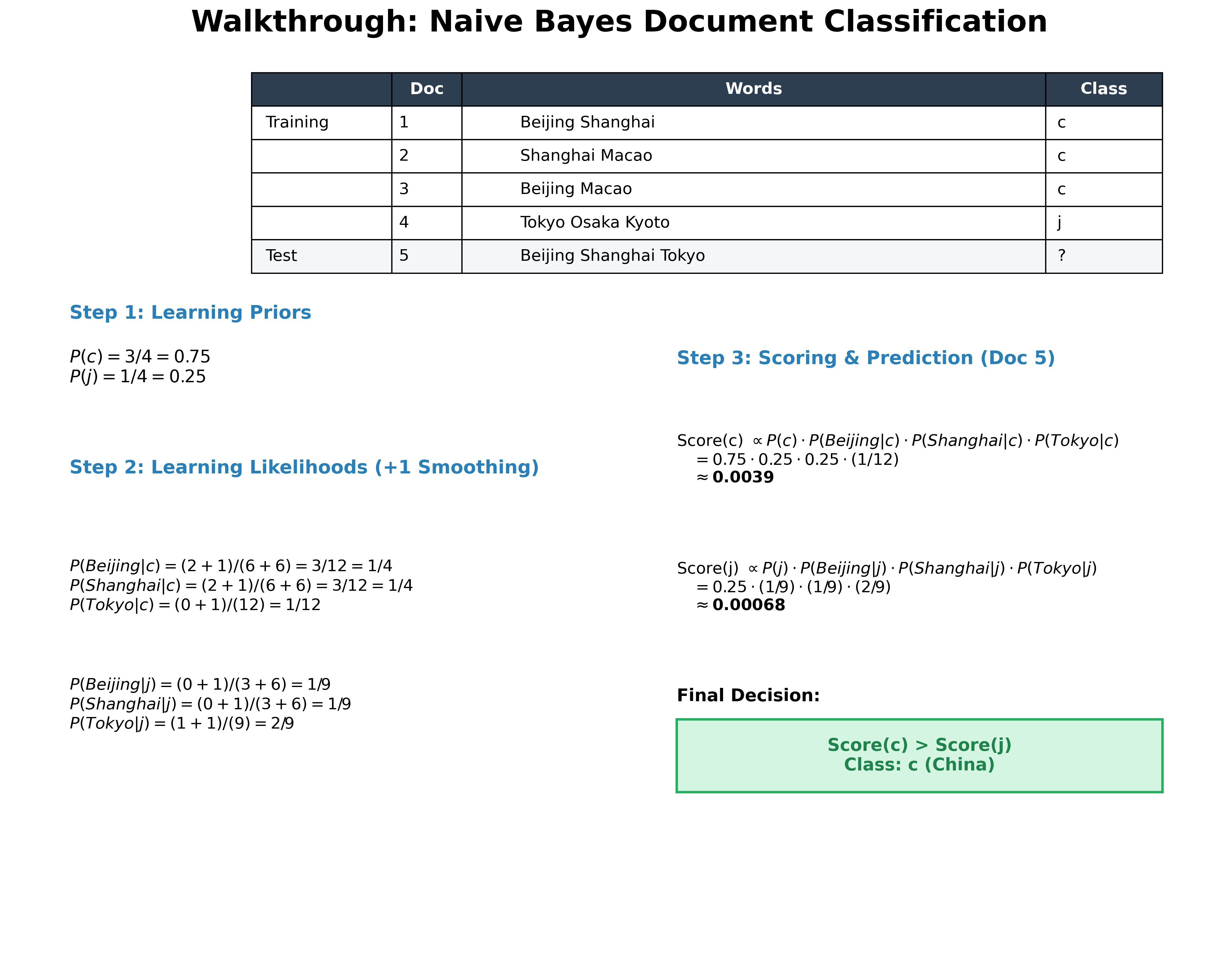
A Detailed Example: Document Classification Walkthrough
To truly understand the mechanics, let's walk through a complete example of classifying a document based on its words.
Scenario: We have a training set of documents labeled as either class c (e.g., China) or class j (e.g., Japan). We want to classify a new test document containing the words "Beijing Shanghai Tokyo".
The Process:
- Priors: Calculate the probability of each class based on the document counts.
- Likelihoods: Calculate the probability of each word appearing in each class (using Laplace smoothing to handle unseen words).
- Scoring: Multiply the Prior by the Likelihoods of the words in the test document.
- Decision: The class with the higher score wins.
The Zero-Frequency Problem and Laplace Smoothing
What happens if a new email contains a word that we've never seen before in our training data (e.g., 'crypto')? The probability P('crypto' | Spam) would be 0. Because we are multiplying probabilities, this single zero would make the entire score for the email zero, which is not ideal.
To solve this, we use Laplace (or Additive) Smoothing. The simplest version is 'add-one' smoothing, where we pretend we've seen every single word one more time than we actually have. This ensures that no word has a zero probability and makes the model more robust to unseen features.
Pros and Cons of Naive Bayes
Pros:
- Fast: It's computationally efficient and requires relatively little training data.
- Works well with high-dimensional data: It performs well on problems with a very large number of features, like text classification.
- Simple to implement: The underlying logic is straightforward.
Cons:
- The "Naive" Assumption: The core assumption of feature independence is often violated in the real world, which can limit its accuracy.
Common Applications:
- Document and text classification
- Spam filters
- Sentiment analysis
- Recommendation systems