Normalization
Normalization is the process of organizing the columns (attributes) and tables (relations) of a relational database to minimize data redundancy and improve data integrity. It involves dividing larger tables into smaller, well-structured tables and defining relationships between them.
The primary goals of normalization are to:
- Eliminate Redundant Data: Storing the same piece of data in multiple places is wasteful and can lead to inconsistencies.
- Prevent Data Anomalies: Anomalies are problems that can occur during data insertion, updates, or deletion. For example, if a customer's address is stored with every order they place, changing their address would require updating multiple records, and it would be easy to miss one.
- Improve Data Integrity: By ensuring that data is stored logically and consistently, normalization makes the database more reliable.
Normalization is achieved by following a set of rules called "normal forms." Let's walk through the most common ones with a Example.
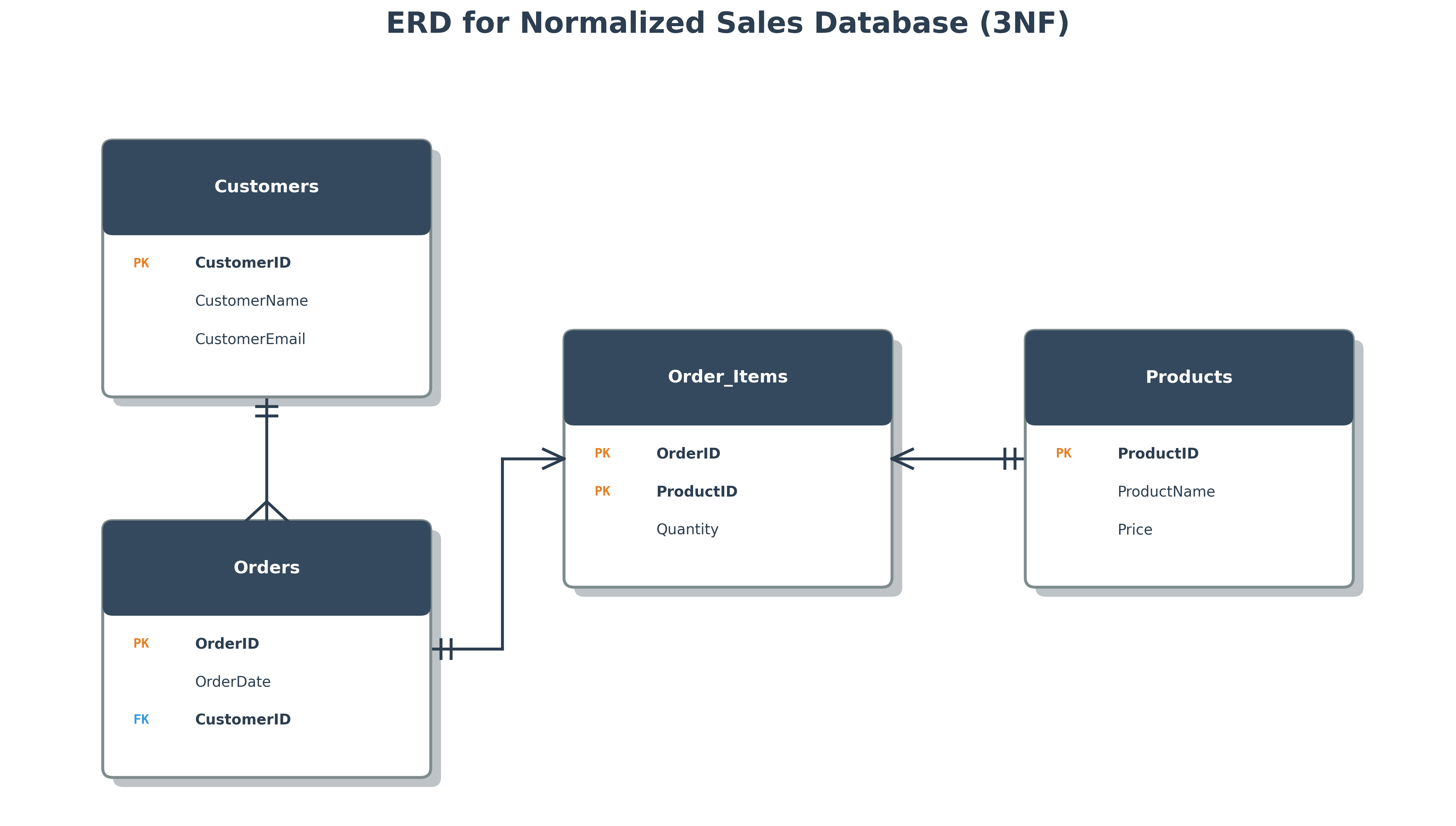
Example: A Sales Order Table
Imagine we start with a single, unnormalized table to track sales orders.
Unnormalized Table
| OrderID | OrderDate | CustomerID | CustomerName | CustomerEmail | ProductID, ProductName, Quantity, Price |
|---|---|---|---|---|---|
| 101 | 2025-09-24 | 55 | Alice Smith | alice@email.com | (P1, Apple, 10, 0.50), (P2, Banana, 5, 0.25) |
| 102 | 2025-09-24 | 82 | Bob Johnson | bob@email.com | (P3, Carrot, 20, 0.10) |
| 103 | 2025-09-25 | 55 | Alice Smith | alice@email.com | (P1, Apple, 15, 0.50) |
This table has several problems:
- The last column contains multiple values (a repeating group), which is hard to query.
- Customer information (Name, Email) is repeated for every order they place.
First Normal Form (1NF): Eliminate Repeating Groups
Rule: Each cell must hold a single, atomic value, and each record must be unique.
To achieve 1NF, we break the repeating product information into separate rows.
1NF Orders Table
| OrderID | OrderDate | CustomerID | CustomerName | CustomerEmail | ProductID | ProductName | Quantity | Price |
|---|---|---|---|---|---|---|---|---|
| 101 | 2025-09-24 | 55 | Alice Smith | alice@email.com | P1 | Apple | 10 | 0.50 |
| 101 | 2025-09-24 | 55 | Alice Smith | alice@email.com | P2 | Banana | 5 | 0.25 |
| 102 | 2025-09-24 | 82 | Bob Johnson | bob@email.com | P3 | Carrot | 20 | 0.10 |
| 103 | 2025-09-25 | 55 | Alice Smith | alice@email.com | P1 | Apple | 15 | 0.50 |
Problem Solved: Each cell now has a single value.
New Problem: We have a lot of redundant data. CustomerName, OrderDate, etc., are repeated for each product in an order. Also, ProductName and Price are repeated every time a product is ordered.
Second Normal Form (2NF): Remove Partial Dependencies
Rule: Must be in 1NF, and all non-key attributes must be fully dependent on the entire primary key. (This rule only applies when there is a composite primary key).
Our primary key for the 1NF table is (OrderID, ProductID).
OrderDate,CustomerID,CustomerName, andCustomerEmaildepend only onOrderID(a part of the primary key). This is a partial dependency.ProductNameandPricedepend only onProductID(another part of the primary key). This is also a partial dependency.
To achieve 2NF, we split the table into three separate tables:
Orders Table
| OrderID | OrderDate | CustomerID |
|---|---|---|
| 101 | 2025-09-24 | 55 |
| 102 | 2025-09-24 | 82 |
| 103 | 2025-09-25 | 55 |
Order_Items Table
| OrderID | ProductID | Quantity |
|---|---|---|
| 101 | P1 | 10 |
| 101 | P2 | 5 |
| 102 | P3 | 20 |
| 103 | P1 | 15 |
Products Table
| ProductID | ProductName | Price |
|---|---|---|
| P1 | Apple | 0.50 |
| P2 | Banana | 0.25 |
| P3 | Carrot | 0.10 |
Problem Solved: We've eliminated the partial dependencies.
New Problem: In the Orders table, we still have a transitive dependency.
Third Normal Form (3NF): Remove Transitive Dependencies
Rule: Must be in 2NF, and every non-key attribute must depend only on the primary key, not on other non-key attributes.
In our new Orders table, the primary key is OrderID.
CustomerIDdepends onOrderID.- However,
CustomerNameandCustomerEmaildepend onCustomerID, which is a non-key attribute. This is a transitive dependency.
To achieve 3NF, we split the Orders table again:
Customers Table
| CustomerID | CustomerName | CustomerEmail |
|---|---|---|
| 55 | Alice Smith | alice@email.com |
| 82 | Bob Johnson | bob@email.com |
Orders Table (Final)
| OrderID | OrderDate | CustomerID |
|---|---|---|
| 101 | 2025-09-24 | 55 |
| 102 | 2025-09-24 | 82 |
| 103 | 2025-09-25 | 55 |
Our database is now in 3NF, with four well-structured tables (Customers, Products, Orders, Order_Items). Data redundancy is minimized.
The Modern Trend: Denormalization for Performance
Historically, the primary driver for normalization was to save disk space, which was incredibly expensive. Today, storage is cheap, but computational power (CPU) and query response time are often more critical.
A highly normalized database often requires complex JOIN operations to retrieve data. For example, to display a full order summary, we would need to join all four of our tables. For a database under heavy load, performing thousands of these complex joins per second can be very slow.
This has led to the practice of denormalization: the process of intentionally adding redundant data back into a database to improve query performance.
Why Denormalize? The goal is to reduce the number of joins needed for frequent queries.
Example:
When displaying a customer's order history, we almost always need the product's name and price. In our 3NF design, getting this requires joining Order_Items with the Products table.
A denormalized approach might be to add ProductName and Price back into the Order_Items table:
Order_Items Table (Denormalized)
| OrderID | ProductID | ProductName | Quantity | PriceAtTimeOfSale |
|---|---|---|---|---|
| 101 | P1 | Apple | 10 | 0.50 |
| 101 | P2 | Banana | 5 | 0.25 |
Advantages:
- Faster Reads: To get an order's details, we now only need to query this one table. No join is needed, which is a huge performance win for a very common operation.
- Historical Accuracy: Storing the price in this table is actually a good thing. What if the price of an Apple changes in the
Productstable tomorrow? This denormalized table preserves the price at the time of the sale.
Disadvantages:
- Increased Storage: We are now storing the product name and price multiple times.
- More Complex Updates: If a product's name is corrected (e.g., a typo fix), we would theoretically need to update it in every
Order_Itemsrecord. In practice, this is often deemed an acceptable trade-off.
Today, database design is a balancing act. While normalization provides a crucial foundation for data integrity, designers often selectively denormalize their databases to optimize for the most frequent and critical read operations, accepting a small amount of redundancy in exchange for speed. This philosophy is also a core principle behind many NoSQL database designs.