Data Mining Methods
Data mining is the process of discovering patterns in large datasets. These patterns can typically be grouped into three main categories: Prediction, Clustering, and Association.
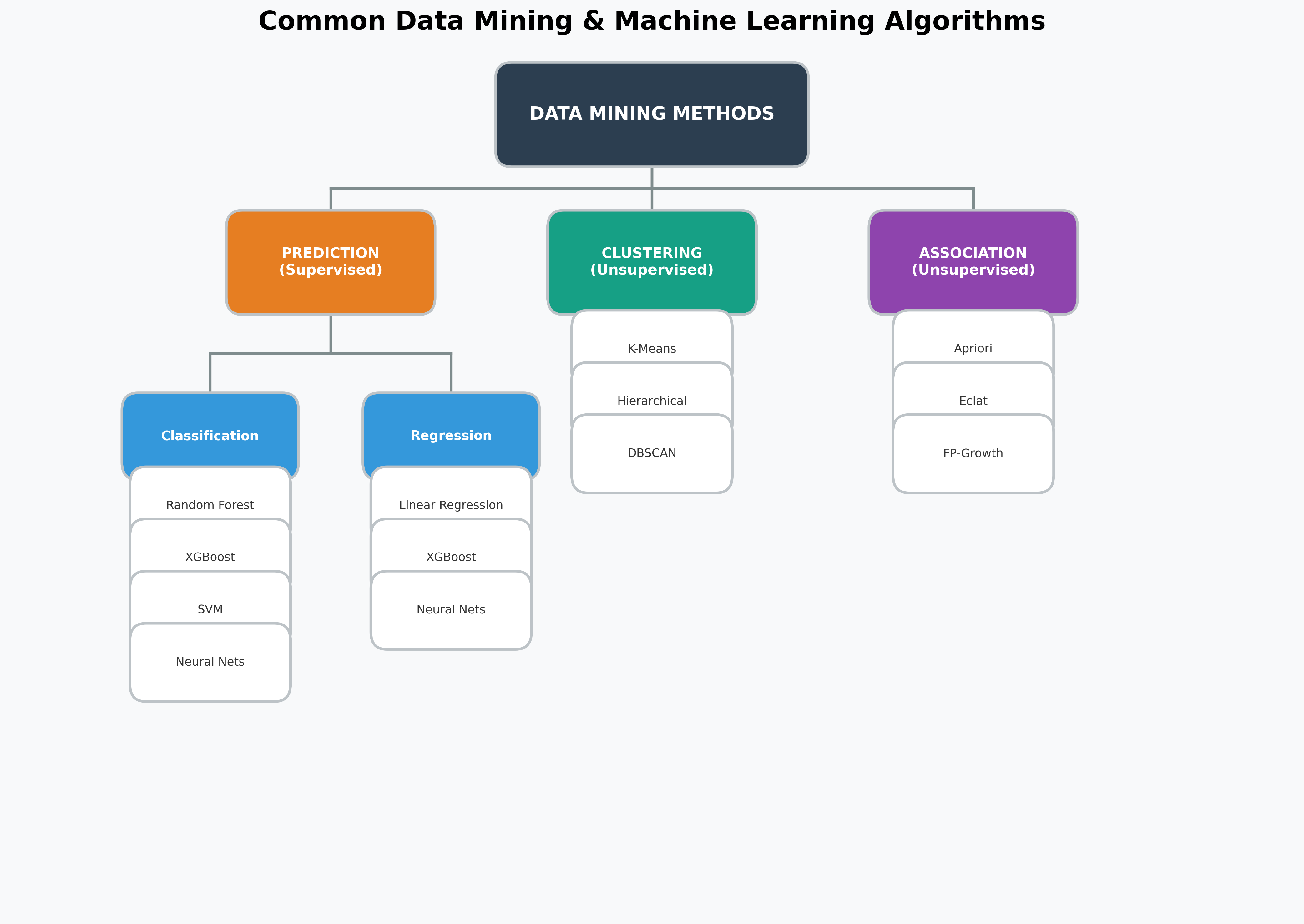
Prediction (Supervised Learning)
Goal: To predict a specific outcome or value based on other input features. This is a supervised learning task because the model learns from historical data that already contains the correct answer.
There are two main types of prediction problems:
Classification: The goal is to predict a categorical label. The output is a class or category.
- Use Cases: Is this email spam or not spam? Will this customer churn or not churn? Is this transaction fraudulent or legitimate?
- Common Algorithms: Random Forest, XGBoost, Decision Trees, Logistic Regression, Support Vector Machines (SVM), Neural Networks (incl. Transformers), Bayesian Classifiers.
Regression: The goal is to predict a continuous numerical value.
- Use Cases: What will the price of this house be? How many units of this product will we sell next month? What will the temperature be tomorrow?
- Common Algorithms: Linear Regression, Random Forest, XGBoost, Gradient Boosting, Neural Networks.
Clustering (Unsupervised Learning)
Goal: To automatically group similar data points together into clusters without any predefined labels. This is an unsupervised learning task because we don't provide the model with a 'correct answer' to learn from; it must find the patterns on its own.
Use Cases:
- Customer Segmentation: Grouping customers with similar purchasing behaviors for targeted marketing campaigns.
- Anomaly Detection: Identifying unusual data points (outliers) that don't fit into any cluster, which could represent fraud or errors.
- Image Segmentation: Grouping pixels in an image to identify objects.
Common Algorithms: K-Means Clustering, Hierarchical Clustering, DBSCAN, Neural Networks (e.g., Self-Organizing Maps).
Association Rule Mining (Unsupervised Learning)
Goal: To discover interesting relationships or 'association rules' among variables in large datasets. This is also an unsupervised learning technique. The most famous application is Market Basket Analysis.
Use Case (Market Basket Analysis):
- Input: Point-of-sale transaction data (i.e., what items were bought together in each transaction).
- Output: Rules that describe how often items are purchased together. A classic example is the rule
{Diapers} -> {Beer}, suggesting that customers who buy diapers also tend to buy beer. - Business Action: Based on these rules, a store might place beer and diapers closer together to increase sales or offer a promotion on one item when the other is purchased.
Common Algorithms: Apriori, Eclat, FP-Growth.