Java Collections Framework
You already know about ArrayList by this time. Now let us look into a few more data structures that are popular.
HashSet
HashSet implements Set interface. In a set, you cannot have duplicate items. In the ArrayList duplicates are allowed but not in a Set.
HashSet syntax:
HashSet<E> myset = new HashSet<E>();
Here also E represents any type of object.
Here is the ArrayList example implemented in a set:
import java.util.HashSet;
public class HashSetDemo {
public static void main(String[] args) {
Set<String> favoriteFruits = new HashSet<String>();
favoriteFruits.add("Mango");
favoriteFruits.add("Banana");
favoriteFruits.add("Apple");
System.out.println(favoriteFruits);
favoriteFruits.remove("Apple");
System.out.println(favoriteFruits);
for (String favoriteFruit : favoriteFruits) {
System.out.println(favoriteFruit);
}
favoriteFruits.add("Banana");
System.out.println(favoriteFruits);
}
}
Output:
[Mango, Apple, Banana]
[Mango, Banana]
Mango
Banana
[Mango, Banana]
Notice the duplicate 'Banana' is not added. You use a Set when you do not want any duplicates to be added. Along with duplicates, a Set does not keep the order in which the elements were added/removed. If you want strict order, then you have to use ArrayList which maintains the order of elements. Javadoc for HashSet: https://docs.oracle.com/javase/9/docs/api/java/util/HashSet.html
HashMap
HashMap implements Map interface. In Map you keep name/value pairs instead of a collection of one type of objects. A key can be of any object type. Keys are unique in HashMap. If you try to add a duplicate key/value, then the existing value for the key will be replaced with the new value.
HashMap syntax:
HashMap<E,E> myMap = new HashMap<E,E>()
Here is an example implementation of HashMap
import java.util.HashMap;
public class HashMapDemo {
public static void main(String[] args) {
Map<String, String> countryCodes = new HashMap<String, String>();
countryCodes.put("US", "United States");
countryCodes.put("MX", "Mexico");
countryCodes.put("CA", "Canada");
System.out.println(countryCodes);
System.out.println(countryCodes.get("US"));
}
}
Output:
{MX=Mexico, US=United States, CA=Canada}
United States
Notice that you use put in HashMap instead of add. Both structures provide get method. get in HashMap receives the name and returns the value
In HashMap you can iterate over the names or values. Here is an example of using foreach to print out the HashMap's key/value pairs.
import java.util.HashMap;
import java.util.Map;
public class HashMapDemo {
public static void main(String[] args) {
HashMap<String, String> countryCodes = new HashMap<String, String>();
countryCodes.put("US", "United States");
countryCodes.put("MX", "Mexico");
countryCodes.put("CA", "Canada");
for (Map.Entry<String, String> countryCode : countryCodes.entrySet()) {
String key = countryCode.getKey();
String value = countryCode.getValue();
System.out.println("key:"+key + ", value:" + value);
}
}
}
Output:
key:MX, value:Mexico
key:US, value:United States
key:CA, value:Canada
You can iterate over keys and values individually also. map.keySet() will provide a set of keys. map.values() will give a collection of values.
Javadoc for HashMap: https://docs.oracle.com/javase/9/docs/api/java/util/HashMap.html
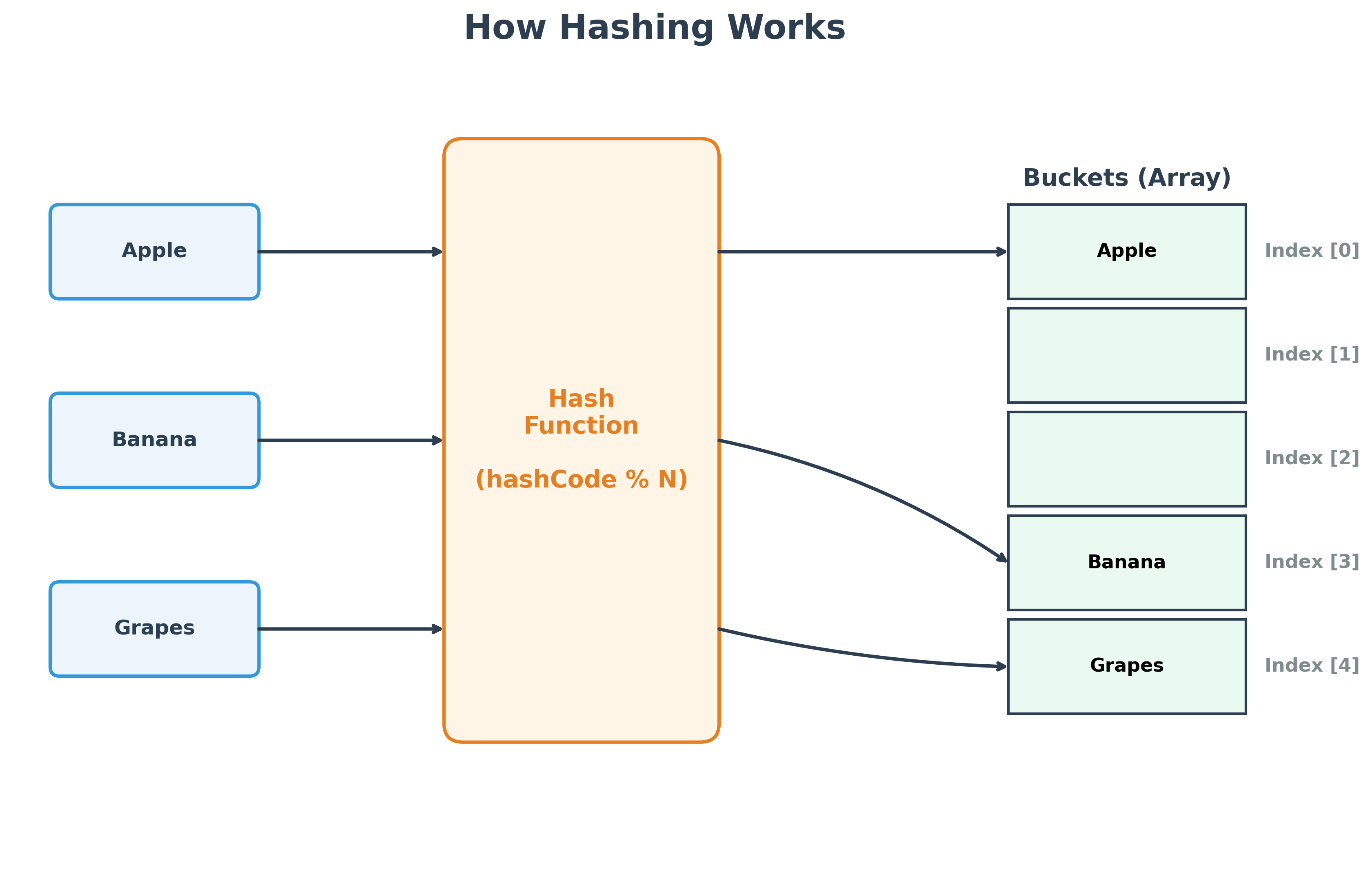
How Hashing Works
Both HashSet and HashMap rely on a mechanism called hashing to store and retrieve data efficiently (often in O(1) constant time).
The Hashing Process
When you add an object to a hash-based collection, the following steps occur:
- HashCode Calculation: The object's
hashCode()method is called to get an integer value. - Index Calculation: This hash code is compressed to fit within the size of the internal array (buckets).
- Formula:
index = hashCode % N - Here,
Nis the size (length) of the array (buckets). - The modulus operator
%ensures the result is always between0andN-1, which are valid array indices.
- Formula:
- Storage: The object is stored in the bucket at that index.
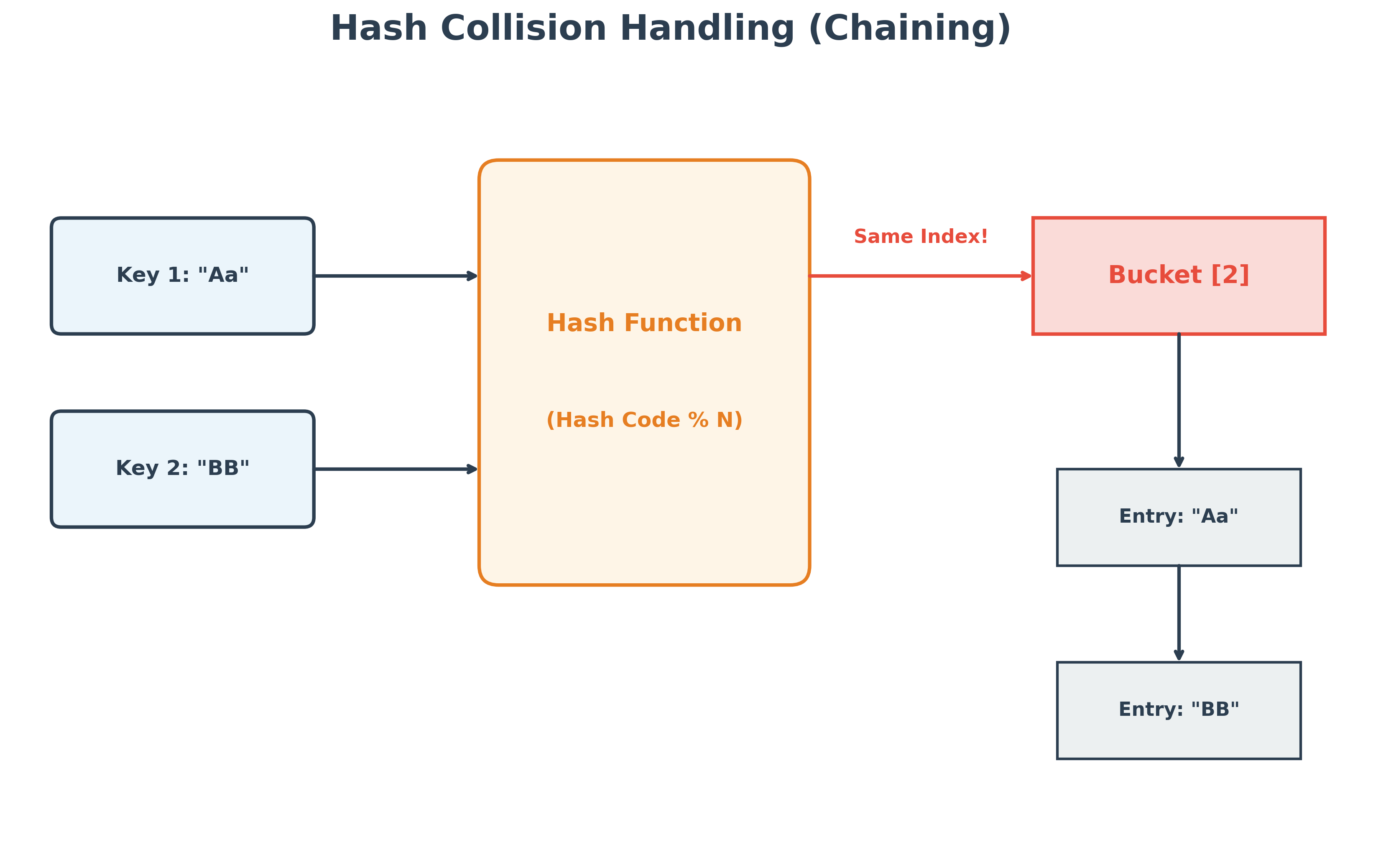
Hash Collisions
A Hash Collision occurs when two different objects produce the same hash code or map to the same bucket index. This is inevitable because the number of possible objects is infinite, but the number of integer hash codes (and array buckets) is finite.
Java handles collisions using Chaining. Each bucket actually holds a linked list (or a balanced tree in modern Java versions). If a collision occurs, the new object is simply added to the list in that bucket.
Important Concepts
- One-Way Process: Hashing is a one-way function. You can generate a hash code from an object, but you cannot regenerate the original object from just the hash code. This is why we store the actual object (key) in the bucket along with the value.
- Performance: If a hash function is poor and causes many collisions, elements will pile up in a few buckets. This degrades performance from O(1) to O(N) because the system has to traverse long linked lists to find your object. This is why overriding
hashCode()correctly is crucial.
Reference for Data Structures: http://www.categories.acsl.org/wiki/index.php?title=Data_Structures