Recurrent Neural Networks (RNNs)
In the Deep Learning chapter, we introduced Recurrent Neural Networks (RNNs) as the specialist architecture for handling sequential data. Let's dive deeper into how they work and what makes them so powerful for tasks involving text, time series, and other ordered data.
The Challenge of Sequential Data
Traditional neural networks (DNNs) and even CNNs have a major limitation: they assume that all inputs are independent of each other. This is a problem when dealing with sequences. For example, to understand the meaning of the word "bank" in a sentence, you need to know the words that came before it ("river bank" vs. "money bank").
RNNs are designed to solve this exact problem. They have a concept of "memory" that allows them to persist information from previous inputs in the sequence to influence the prediction for the current input.
The Core Idea: A Loop for Memory
An RNN works by performing the same task for every element of a sequence, with the output of the previous element being fed as an input to the current element. This is achieved by a loop within the network's architecture.
At each step t in the sequence, the RNN cell takes two inputs:
- The current input data
x(t). - The hidden state
h(t-1)from the previous step.
It then produces two outputs:
- The prediction for the current step
y(t). - The new hidden state
h(t), which is then passed to the next step in the sequence.
This hidden state acts as the network's memory, carrying information from the past.
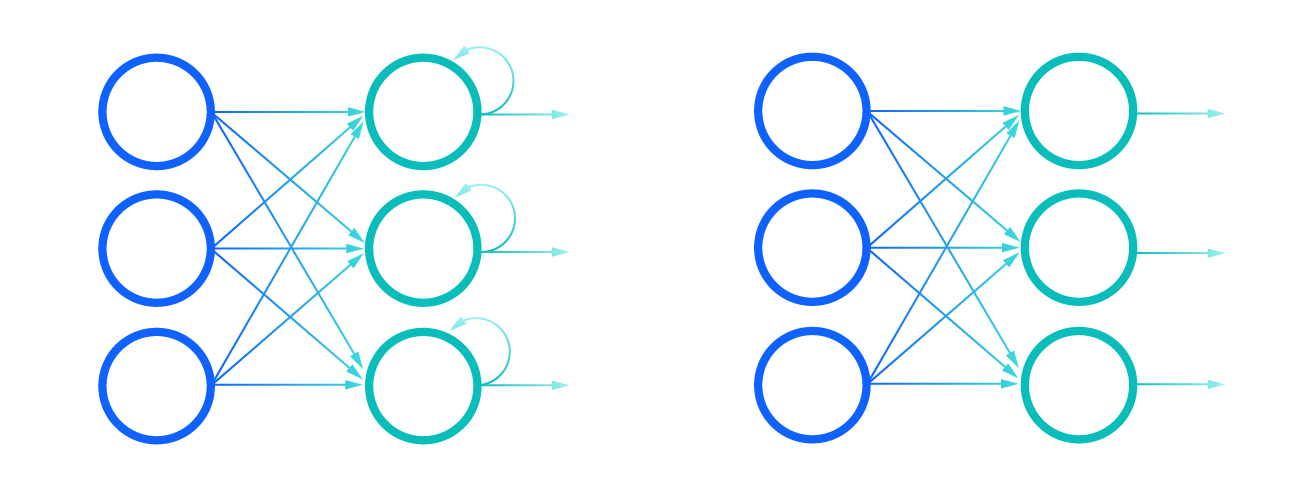
RNN Architectures
Depending on the problem, the structure of the inputs and outputs can change. This leads to several common RNN architectures.
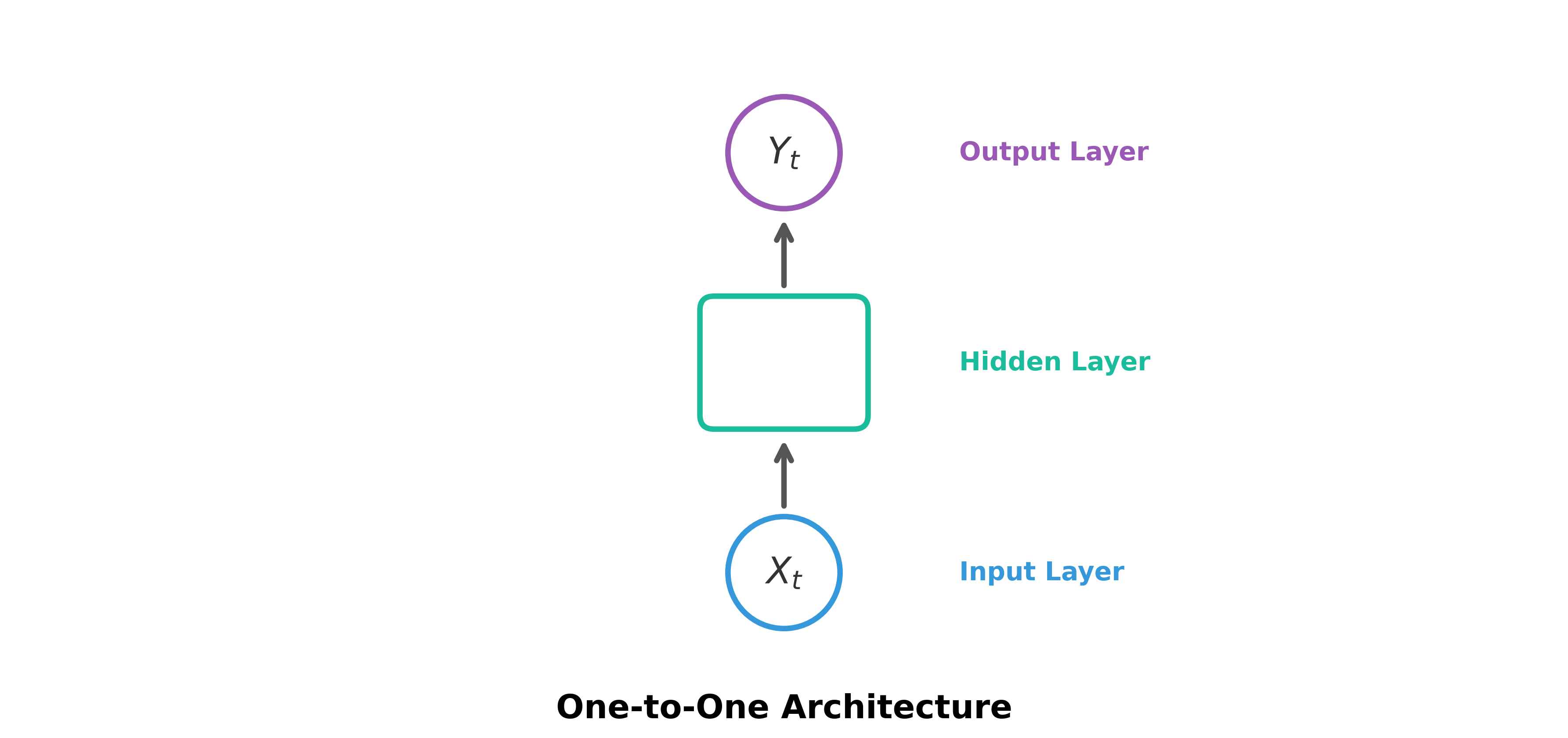
One-to-One: This is the standard, non-sequential neural network (e.g., image classification).
- Input (): A single input (e.g., an image).
- Hidden Layer: Processes the input.
- Output (): A single output (e.g., "Cat" or "Dog").
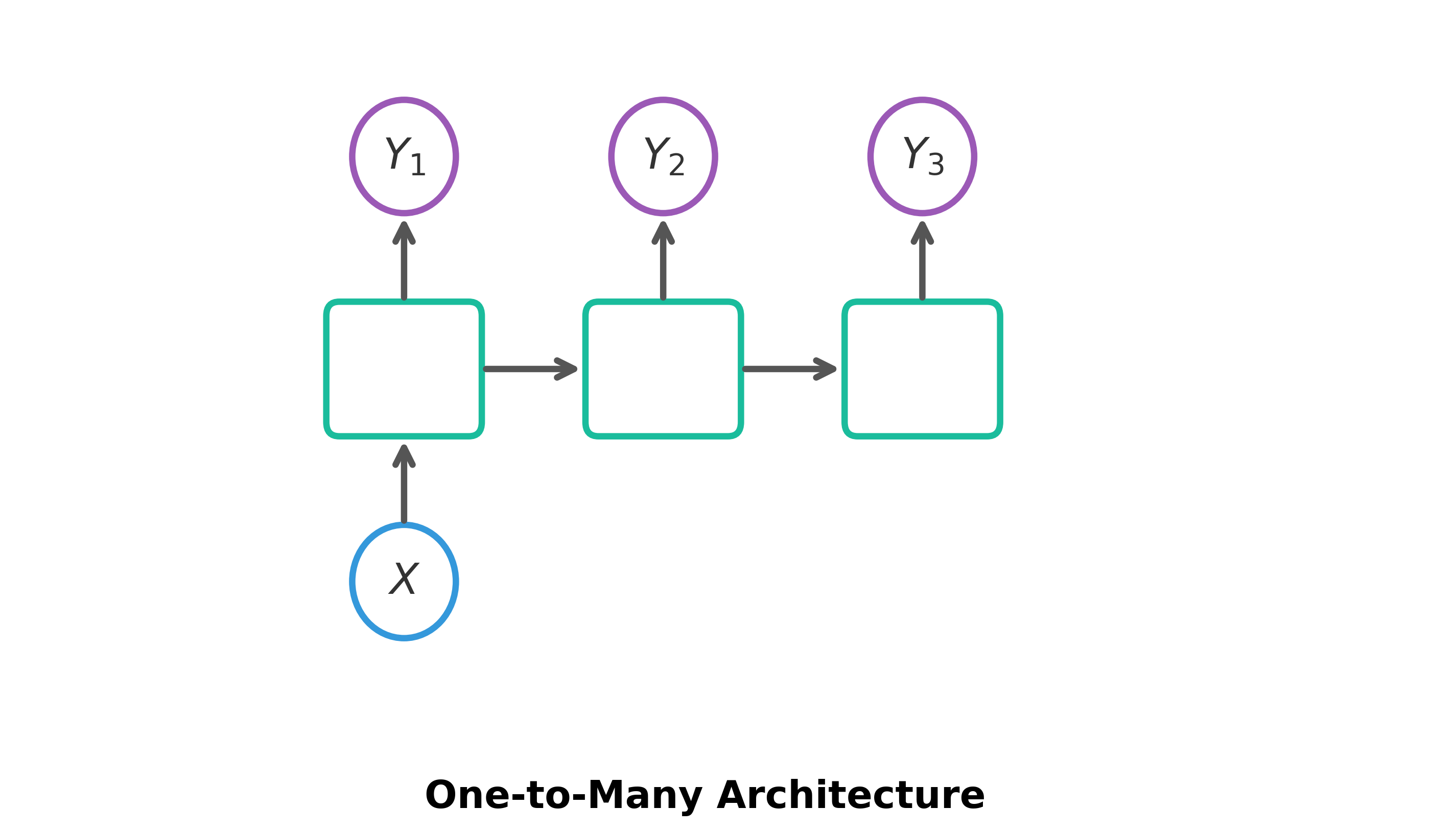
One-to-Many: Takes a single input and produces a sequence of outputs.
- Input (): Single input (e.g., an image).
- Hidden Layers: Process the input and pass state forward.
- Outputs (): A sequence of outputs (e.g., words in a caption).
- Example: Image Captioning.
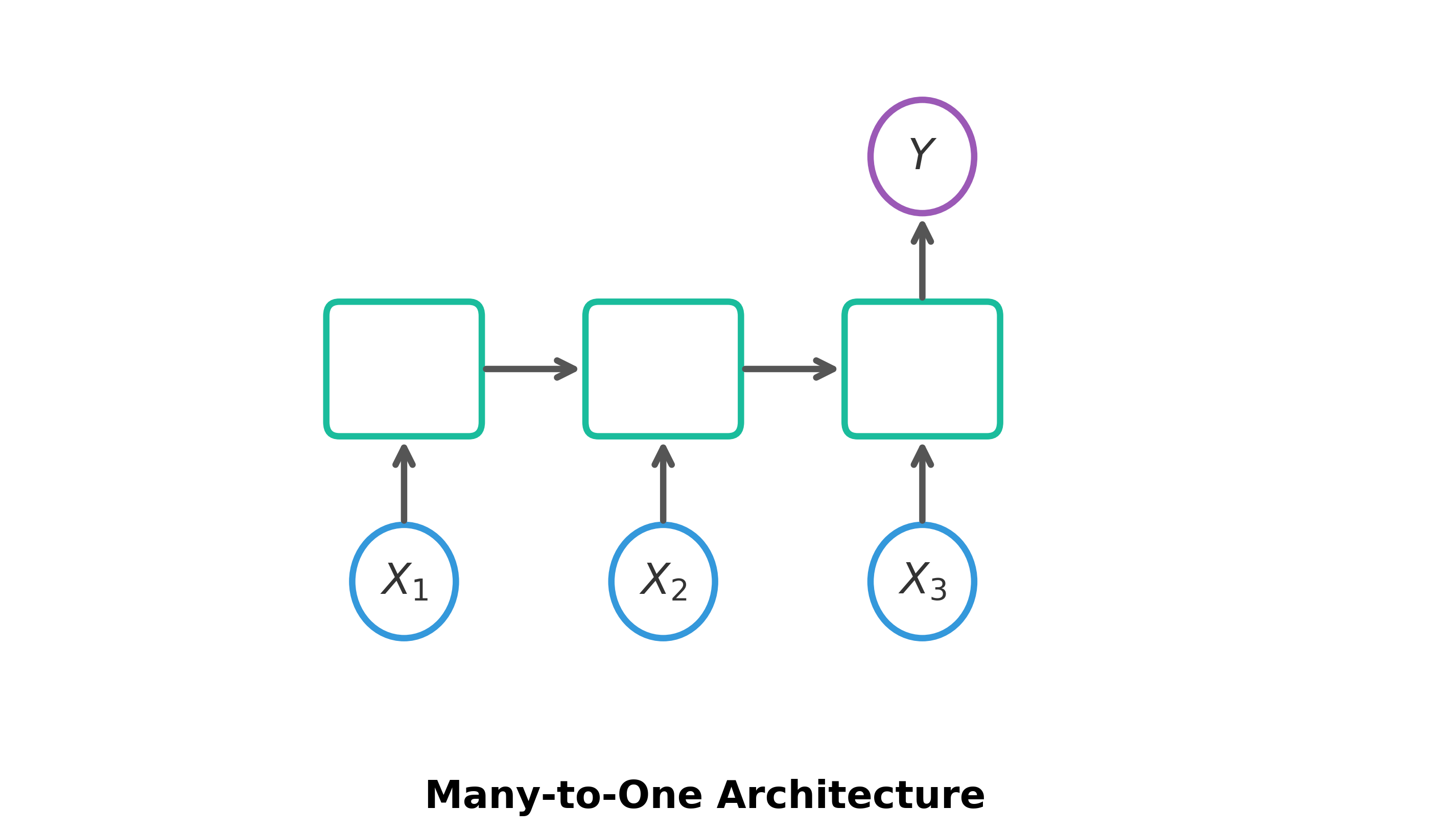
Many-to-One: Takes a sequence of inputs and produces a single output.
- Inputs (): A sequence of inputs (e.g., words in a sentence).
- Hidden Layers: Aggregate information from the sequence.
- Output (): A single final output (e.g., Sentiment Score).
- Example: Sentiment Analysis.
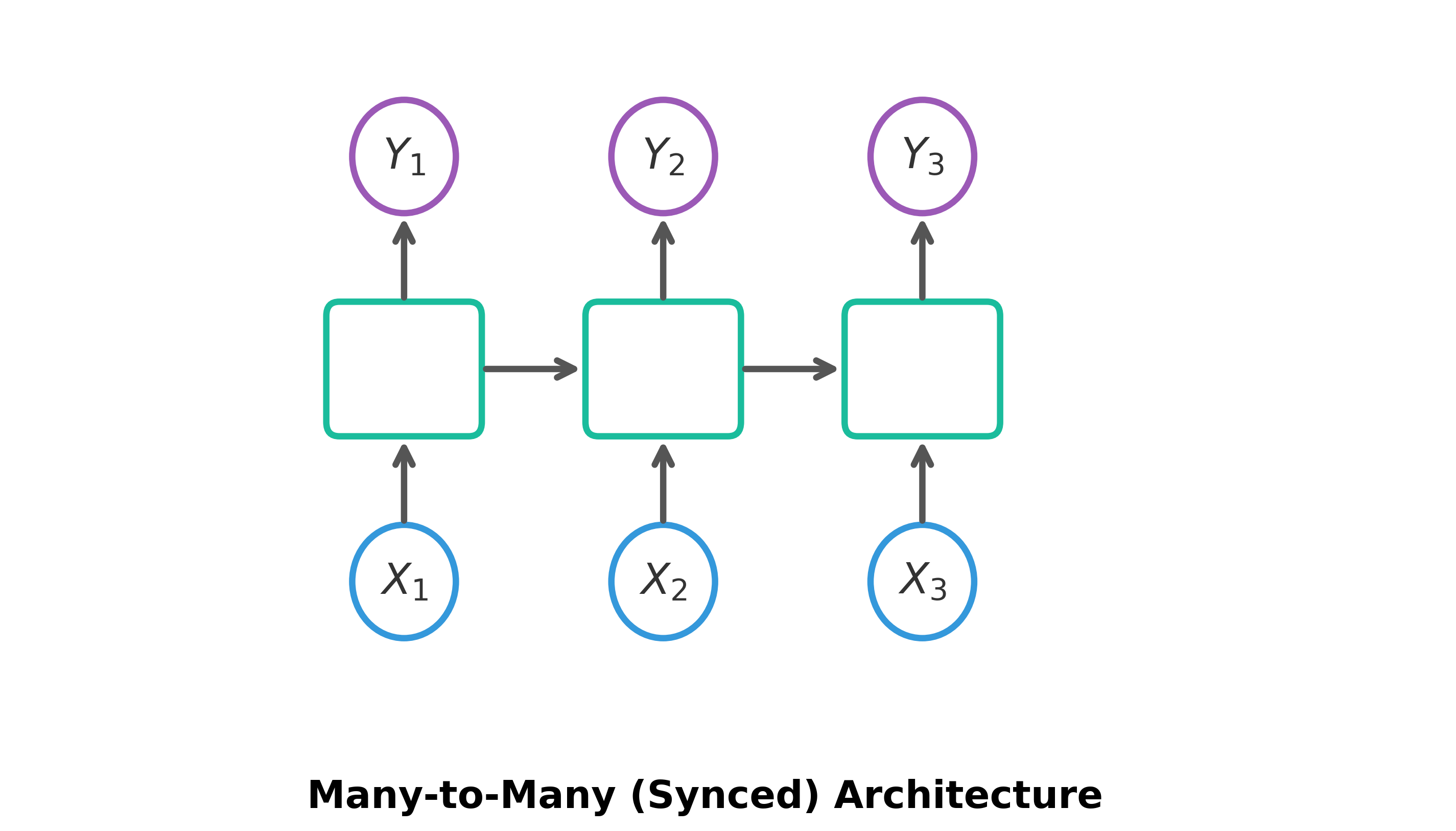
Many-to-Many (Synced): Takes a sequence of inputs and produces a synchronized sequence of outputs.
- Inputs (): Sequence of inputs (e.g., video frames).
- Outputs (): Corresponding sequence of outputs (e.g., label for each frame).
- Example: Video Classification.
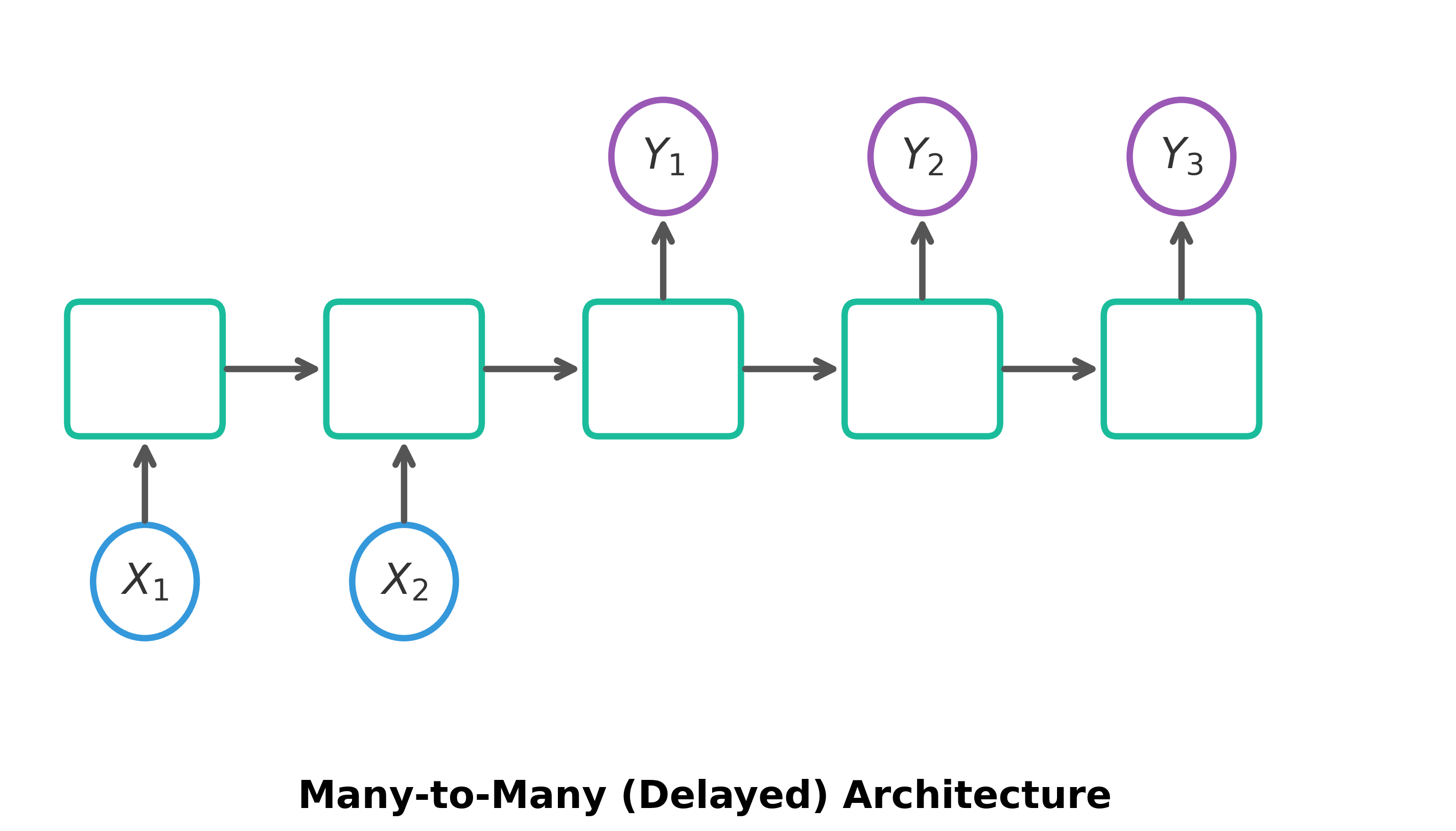
Many-to-Many (Delayed/Seq2Seq): Takes a sequence of inputs and produces a sequence of outputs after the entire input sequence has been consumed.
- Encoder (): Reads the input sequence (e.g., sentence in English).
- Decoder (): Generates the output sequence (e.g., sentence in French) after encoding is complete.
- Example: Machine Translation.
The Vanishing Gradient Problem
A major challenge with simple RNNs is the vanishing gradient problem. During backpropagation, the gradients can become exponentially smaller as they are passed back through time. This means that the network struggles to learn long-range dependencies (i.e., connecting a word at the end of a sentence to a word at the very beginning).
To solve this, more advanced RNN variants were created:
- Long Short-Term Memory (LSTM): LSTMs have a more complex cell structure with "gates" (an input gate, a forget gate, and an output gate) that allow the network to selectively remember or forget information over long periods.
- Gated Recurrent Unit (GRU): GRUs are a slightly simpler and more computationally efficient version of LSTMs that also use gates to manage the flow of information and combat the vanishing gradient problem.
These architectures, especially LSTMs and GRUs, are the foundation of most modern sequence processing tasks.