Recommendation Systems
Recommendation systems are one of a machine learning's most common and impactful applications in the real world. From Amazon suggesting products to Netflix recommending movies, their goal is to predict a user's interest in an item and surface relevant content from a massive catalog.
The end goal is not only to improve sales but also to keep customers engaged by helping them discover products they will love.
The Core Idea: Collaborative Filtering
The most common technique used in recommendation systems is Collaborative Filtering. The core idea is simple: leverage the "wisdom of the crowd." Instead of looking at the attributes of an item (like its genre or price), it makes recommendations based on the past behavior and preferences of similar users or items.
The Data: The User-Item Matrix
To understand how collaborative filtering works, we first need to understand how the data is structured. The data is typically organized into a large user-item matrix (also called a utility matrix).
- The rows represent all the users.
- The columns represent all the items (e.g., movies, products).
- The values in the matrix are the ratings that a user has given to an item.
This matrix is usually very sparse, meaning most cells are empty because a typical user has only rated a small fraction of the available items.
Types of Collaborative Filtering
There are two main approaches to collaborative filtering:
User-Based Collaborative Filtering
The Idea: 'People who are like you also like...'
This method finds users who have a similar rating history to you. It then recommends items that those similar users liked but that you haven't yet seen.
Example: If John and Joe both rated Movies A, B, and C highly, they are considered similar. When a new movie, D, comes out that John loves, the system will recommend Movie D to Joe.
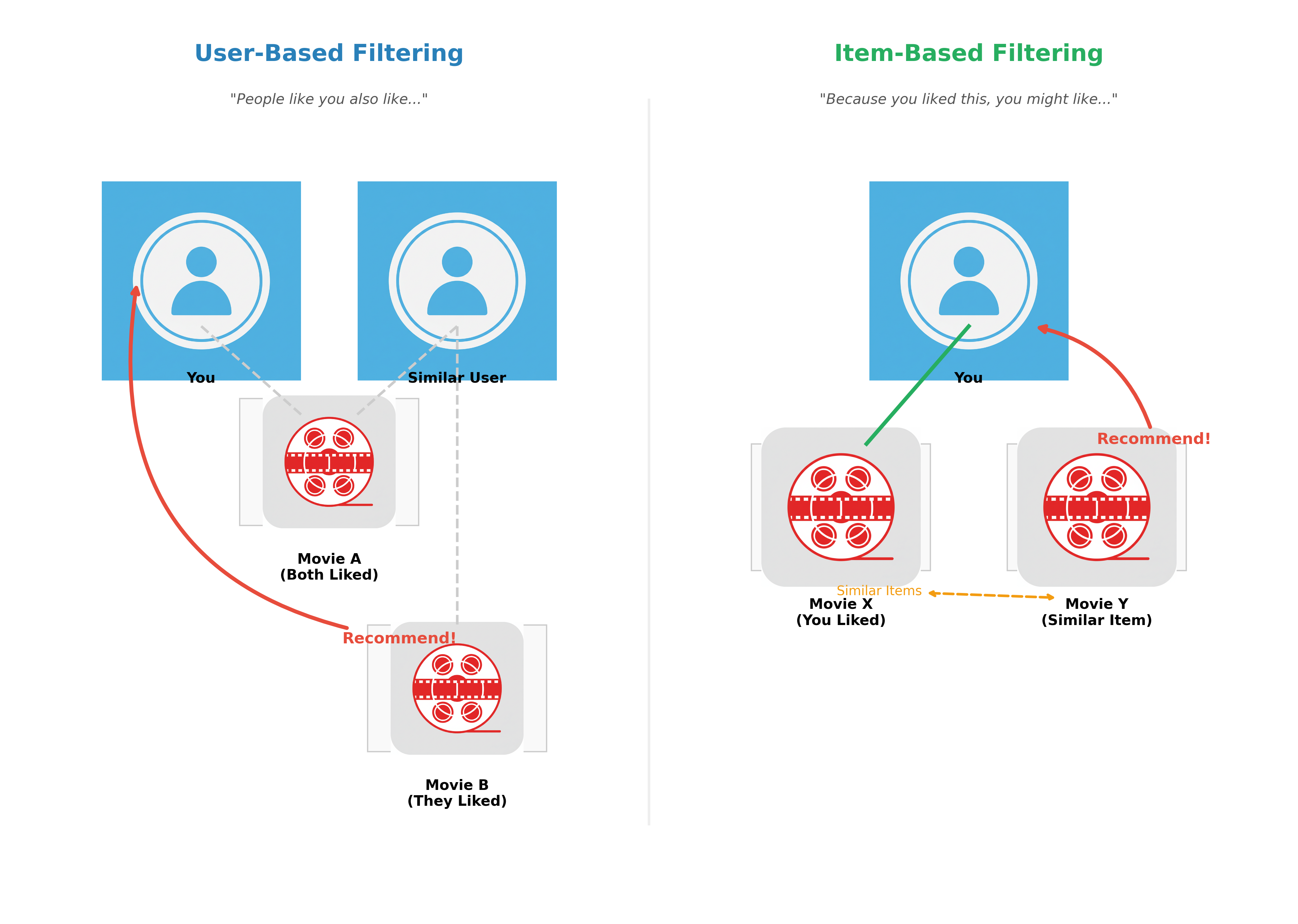
Item-Based Collaborative Filtering
The Idea: 'Because you liked this item, you might also like...'
This method finds items that are similar to the ones you have rated highly. For example, if you loved Star Wars: A New Hope, the system might find that people who liked that movie also liked The Empire Strikes Back, and it will recommend that to you.
This approach is often preferred in practice because item-to-item similarities are generally more stable over time than the dynamic tastes of users.
Measuring Similarity
To determine which users or items are "similar," the system represents each user (or item) as a vector in the user-item matrix. It then calculates the similarity between these vectors using mathematical metrics like Cosine Similarity or Pearson Correlation.
Challenges of Collaborative Filtering
While powerful, collaborative filtering has some well-known challenges:
- The Cold Start Problem: How do you make recommendations for a brand-new user with no rating history? Or how do you recommend a brand-new item that no one has rated yet? The model has no data to work with in these cases.
- Data Sparsity: The user-item matrix is mostly empty. This can make it difficult to find users or items with enough overlapping ratings to calculate a reliable similarity score.
- Popularity Bias: The system tends to recommend popular items more frequently, which can limit the discovery of new or niche items.
Other Types of Recommenders
To overcome these challenges, real-world systems often use a Hybrid Approach, combining collaborative filtering with other methods like:
- Content-Based Filtering: Recommends items based on their attributes. For example, if you watch a lot of sci-fi movies, it will recommend other sci-fi movies.
- Demographic Filtering: Recommends items based on the user's demographic information (e.g., age, location).