K-Means Clustering
K-Means is one of the most popular and straightforward clustering algorithms. As an unsupervised learning algorithm, its goal is to find natural groupings in unlabeled data. Specifically, K-Means partitions data into a pre-defined number (K) of distinct, non-overlapping clusters.
The K-Means Algorithm: Step-by-Step
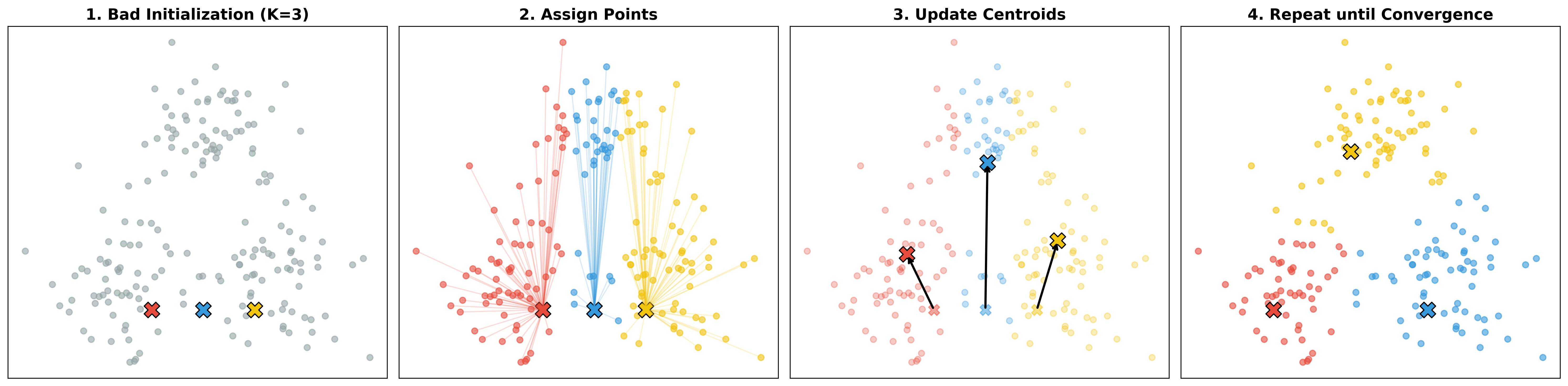
The algorithm works iteratively to find the best placement for the cluster centers, or centroids. Here’s an intuitive breakdown of the process:
- Choose K: First, you must decide how many clusters you want to find and specify this number as
K. - Initialize Centroids: The algorithm randomly places
Kcentroids in the feature space. - Assign Step: Each data point is assigned to the cluster of its nearest centroid (typically using Euclidean distance).
- Update Step: The position of each centroid is recalculated as the mean (the average) of all the data points assigned to its cluster.
- Repeat: Steps 3 and 4 are repeated until the centroids no longer move significantly, meaning the clusters have stabilized and the algorithm has converged.
The Big Challenge: How to Choose K?
The biggest challenge in using K-Means is that you have to choose the number of clusters, K, yourself. How do you know if you should look for 3 clusters or 5?
A common technique to help with this decision is the Elbow Method.
- Run the K-Means algorithm for a range of different
Kvalues (e.g., from 1 to 10). - For each
K, calculate the Sum of Squared Errors (SSE) within each cluster. This measures the total distance between each point and its cluster's centroid. - Plot
Kversus the SSE.
As K increases, the SSE will always decrease. However, you are looking for the "elbow" point on the graph—the point where the rate of decrease slows down significantly. This point of diminishing returns is often a good choice for K.
Strengths and Weaknesses of K-Means
Pros:
- Fast and Scalable: It is computationally efficient and works well on large datasets.
- Simple to understand and implement.
Cons:
- Must choose K manually: The Elbow Method is a heuristic and doesn't always give a clear answer.
- Sensitive to initialization: The initial random placement of centroids can lead to different final clusters. It's common to run the algorithm multiple times with different random seeds.
- Assumes spherical clusters: It struggles to find clusters that are non-spherical (e.g., elongated or oddly shaped).
- Sensitive to outliers: Outliers can pull centroids away from the true center of a cluster.