MLOps: Maturity Levels & Automation
Machine Learning Operations (MLOps) is a set of practices that aims to deploy and maintain machine learning models in production reliably and efficiently. Based on Google Cloud's MLOps framework, maturity is divided into three levels based on the degree of automation and the implementation of CI/CD.
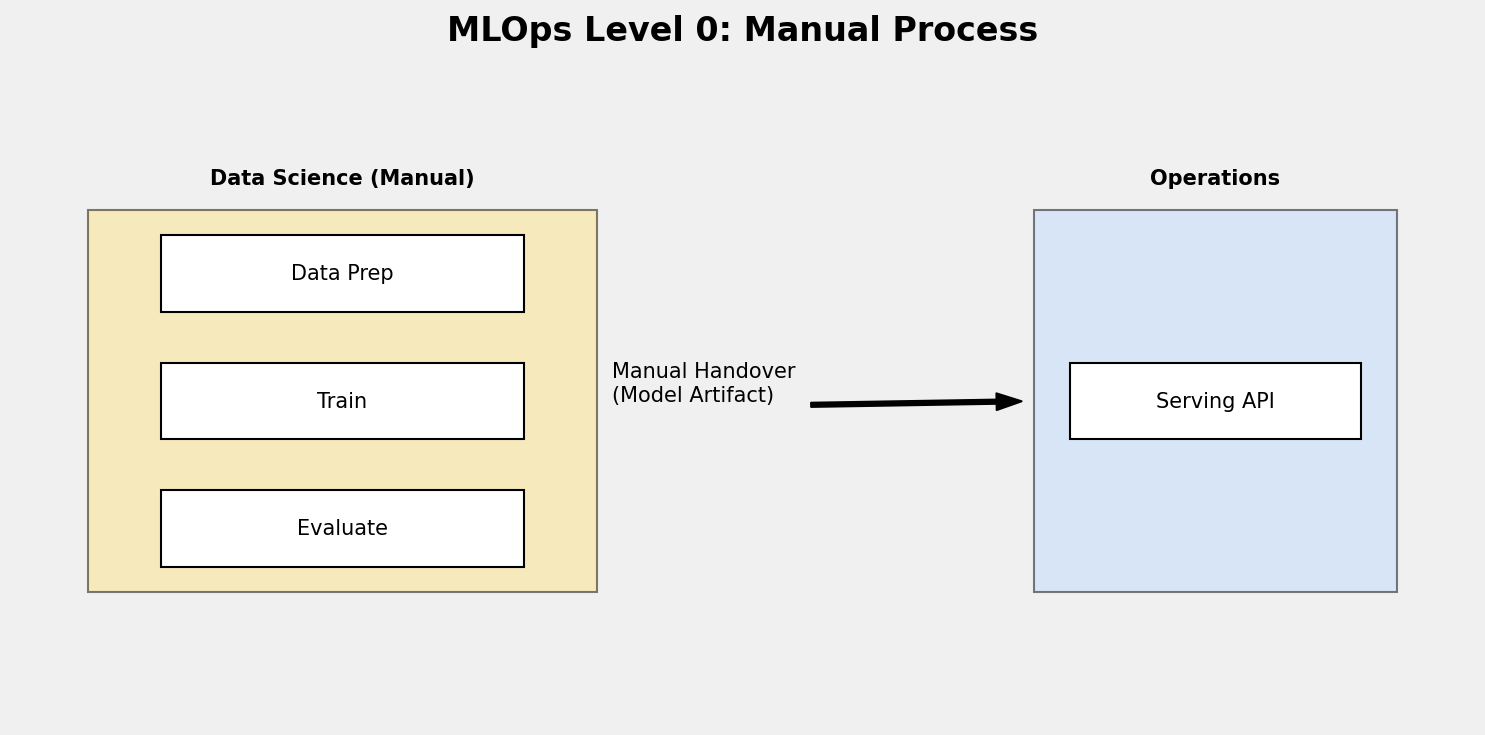
MLOps Level 0: Manual Process
At this level, the entire process of building and deploying models is manual and script-driven.
- Process: Data scientists manually perform data extraction, analysis, preparation, and model training.
- Handover: The output is a trained model artifact (like a
.joblibor.h5file) handed over to the engineering team. - Challenges:
- No CI/CD: Since changes are infrequent, automation is often ignored.
- No Monitoring: There is no automated way to detect performance degradation or data drift.
- Siloed Teams: Data science and operations work in isolation.
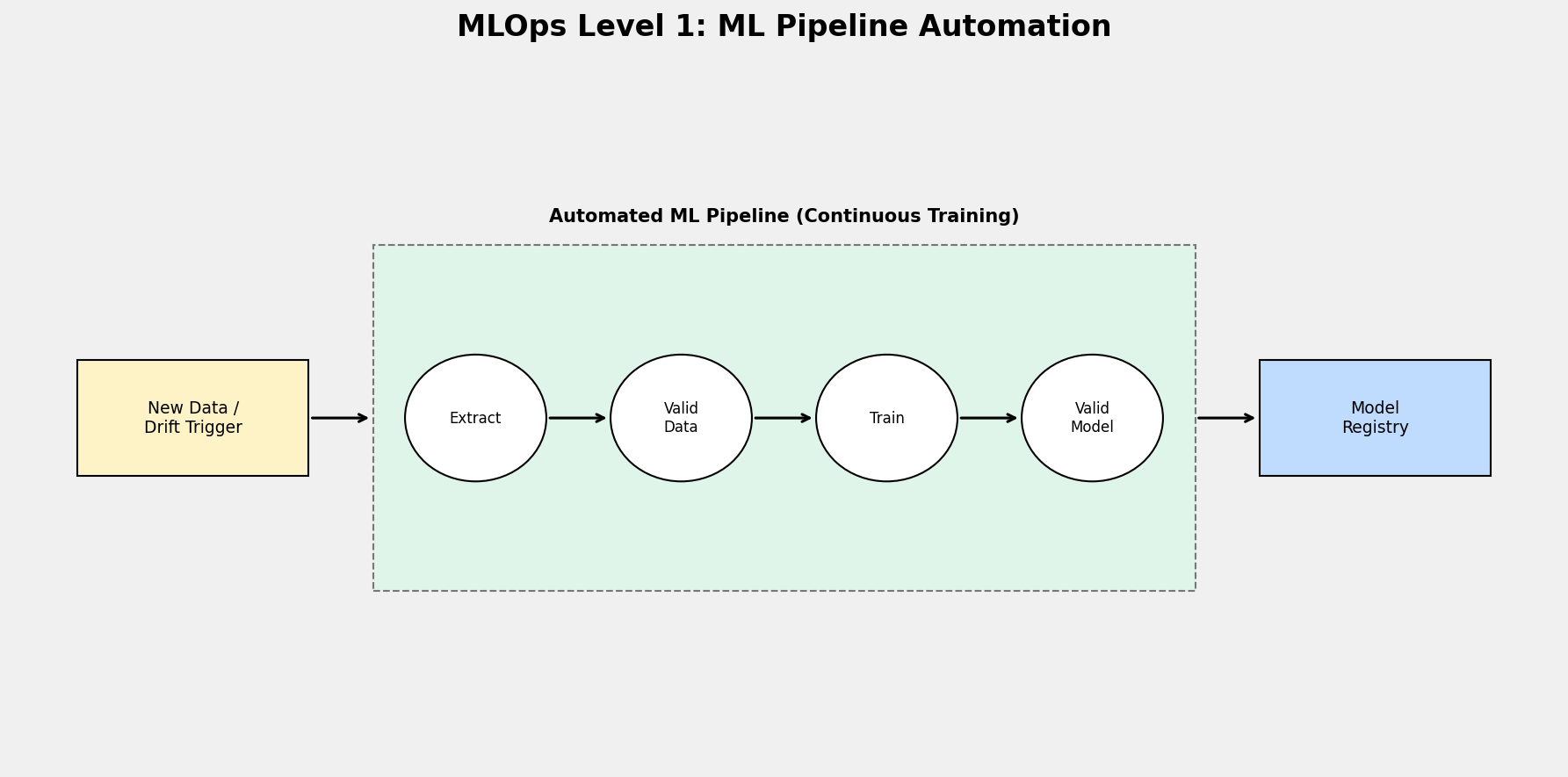
MLOps Level 1: ML Pipeline Automation
The goal here is Continuous Training (CT). The model training pipeline is automated, allowing the model to be retrained whenever new data is available or performance drops.
- Automation: The entire pipeline (Data Prep -> Train -> Validate) is orchestrated and automated.
- Triggers: Retraining can be triggered by a schedule, new data availability, or detected model drift.
- Continuous Delivery (Model): Once a model is trained and validated by the pipeline, it is automatically deployed to production.
- Metadata Management: Information about each pipeline execution (parameters, metrics) is recorded.
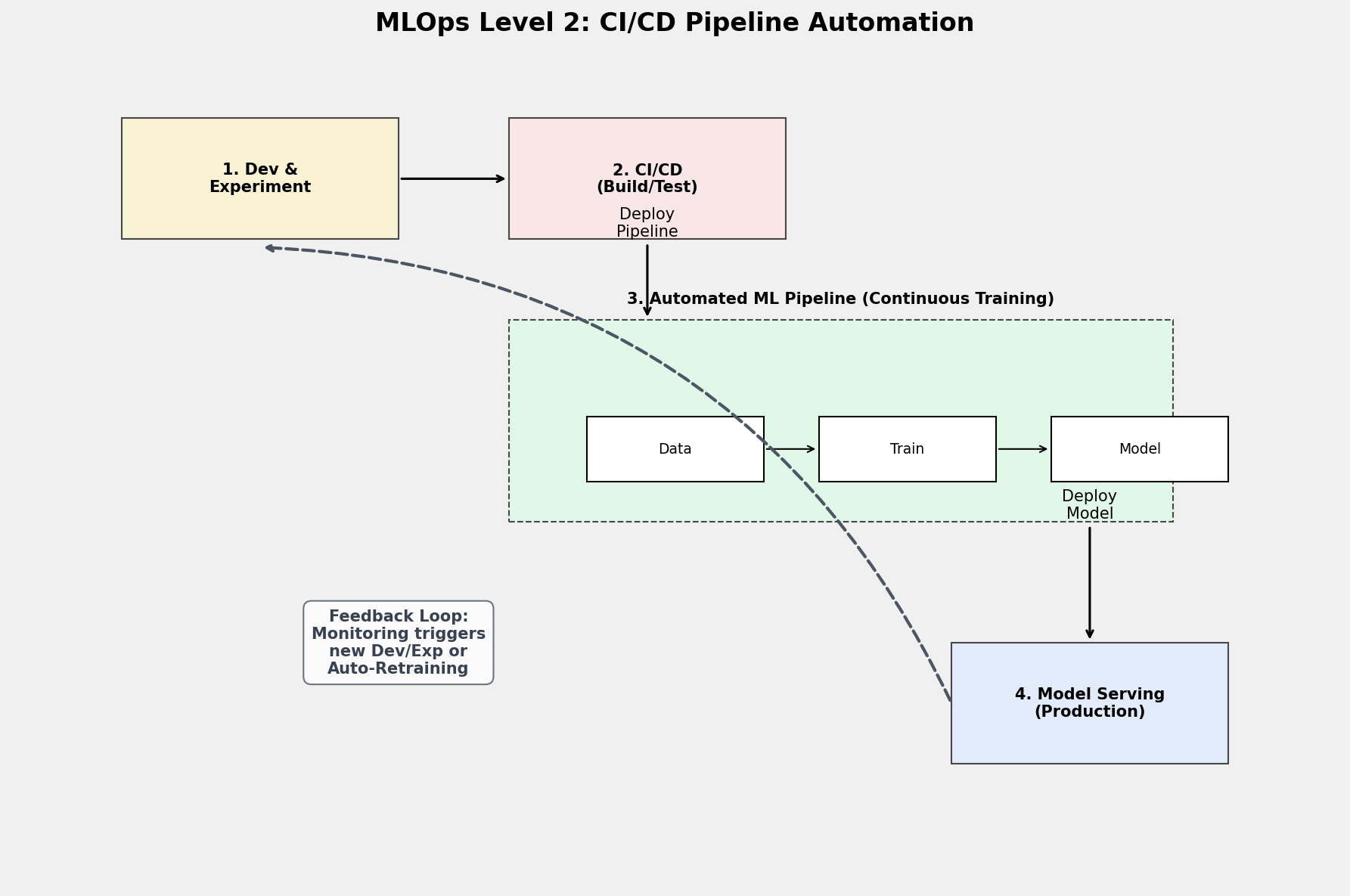
MLOps Level 2: CI/CD Pipeline Automation
At this most advanced level, you don't just automate the training of models; you automate the deployment of the pipelines themselves. This is suitable for teams that experiment with new ideas and need to push new pipeline implementations to production rapidly.
- Full CI/CD:
- CI (Continuous Integration): New pipeline code is automatically built and tested.
- CD (Continuous Delivery): The new pipeline implementation is automatically deployed to the target environment.
- Rapid Experimentation: Data scientists can experiment with new feature engineering or model architectures and push them to production with high confidence.
- Continuous Monitoring: Real-time monitoring of model performance in production serves as the feedback loop to trigger either retraining (Level 1) or a new experimentation cycle (Level 2).
Summary Table
| Feature | Level 0 | Level 1 | Level 2 |
|---|---|---|---|
| Main Focus | Deploying a model | Continuous Training (CT) | CI/CD of ML Pipelines |
| Workflow | Manual / Interactive | Automated Pipeline | Fully Automated CI/CD |
| Deployment | Manual Model Handover | Automated Model Deployment | Automated Pipeline Deployment |
| Monitoring | None / Manual | Performance Monitoring | Continuous Feedback Loop |