The CAP Theorem (Brewer's Theorem)
The CAP theorem, first proposed by Eric Brewer, is a fundamental principle that governs the design of distributed data systems. It states that it is impossible for a distributed data store to simultaneously provide more than two out of the following three guarantees:
- Consistency
- Availability
- Partition Tolerance
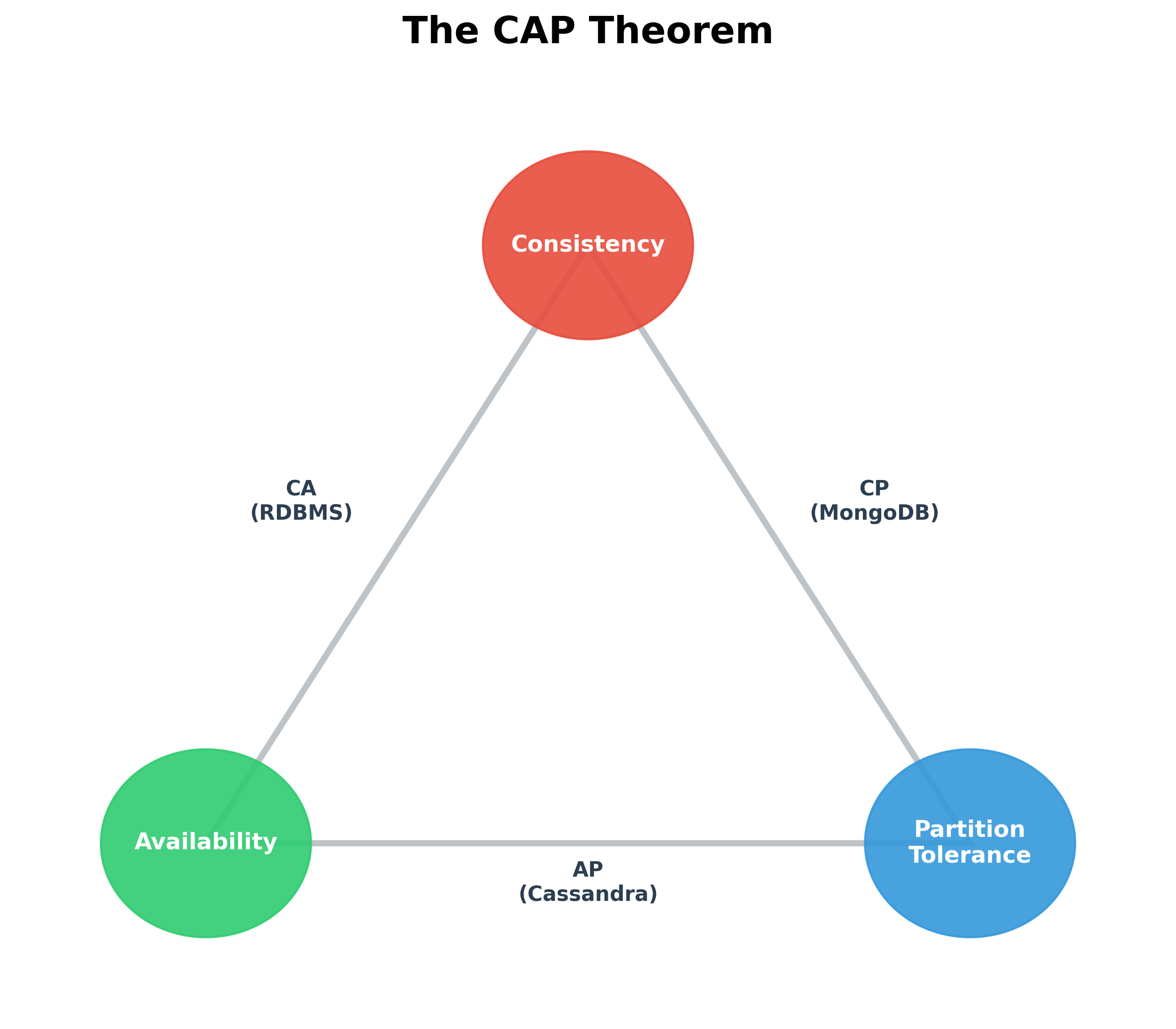
Note on RDBMS Classification: Traditional RDBMS (like MySQL or PostgreSQL) are typically classified as CA systems because, in a single-node configuration, they guarantee Consistency and Availability but do not handle network partitions (Partition Tolerance). However, in a distributed cluster, most RDBMS prioritize Consistency over Availability during a network partition, effectively behaving as CP systems to prevent data corruption.
Let's break down each guarantee with a clear analogy.
1. Consistency
What it means: Every read operation receives the most recent write or an error. In a system with multiple replicas (copies) of the data, consistency means that all clients see the same data at the same time, no matter which replica they connect to.
Analogy: A Bank Account Balance Imagine you have 100.
- Your new balance is $600.
- A consistent system guarantees that from that moment on, anyone, anywhere, who queries your account balance will see exactly 500 balance again.
2. Availability
What it means: Every request made to the system receives a (non-error) response. The system is always online and ready to work, without any guarantee that the response contains the most recent write.
Analogy: An ATM Machine
- When you go to an ATM, you expect it to respond. You insert your card, and it either gives you money or tells you why it can't.
- An available system guarantees a response. It won't just freeze or time out. Even if it can't connect to the main bank to get the absolute latest balance, it might operate on slightly older, cached data, but it will respond.
3. Partition Tolerance
What it means: The system continues to operate even if the network connection between its different nodes (servers) is broken. This is called a network partition.
Analogy: Two Bank Branches During a Network Outage
- Imagine a bank has two branches, one in New York and one in London. The data for your account is replicated in both locations.
- A transatlantic cable is cut, and the two branches can no longer communicate. This is a network partition.
- A partition-tolerant system must continue to function. The New York branch should still be able to serve its customers, and the London branch should still be able to serve its customers, despite the communication failure between them.
The Trade-Off: Why You Can Only Pick Two
In any real-world distributed system, network partitions are a fact of life. Servers can fail, and network links can break. Therefore, a distributed system must have Partition Tolerance (P).
This means the real choice is always between Consistency and Availability when a partition occurs.
The Scenario: The Network Partition Happens
The New York and London branches can't talk to each other. Alice, who is in New York, wants to deposit 500). What should the system do?
Choice 1: Prioritize Consistency over Availability (A CP System)
To guarantee consistency, the system must ensure that the balance can never be wrong.
- When Alice tries to deposit $100 in New York, the New York server knows it can't update the London server.
- To prevent an inconsistency (where New York shows 500), the system must refuse the write request. It might even make one of the branches (e.g., London) completely read-only or shut it down until the partition is healed.
- The Trade-off: The system is Consistent (no one can read a wrong value) but it is Not Available (Alice's deposit request was denied).
Real-world CP databases: MongoDB (in its default configuration), HBase, Redis. These are often used for financial systems, e-commerce backends, or any application where data correctness is the absolute top priority.
Choice 2: Prioritize Availability over Consistency (An AP System)
To guarantee availability, the system must always respond to requests.
- When Alice tries to deposit 600.
- Meanwhile, if Bob in London queries her balance, the London server, unable to get the update, will report the last value it knew: $500. This is known as stale data.
- The system is designed to resolve this conflict later when the network partition is healed. This is called eventual consistency.
- The Trade-off: The system is Available (it accepted Alice's deposit and responded to Bob's read) but it was temporarily Inconsistent.
Real-world AP databases: Apache Cassandra, Amazon DynamoDB, CouchDB. These are often used for social media feeds, user comment systems, or applications where being online is more critical than every piece of data being 100% up-to-date at all times.