Introduction to Big Data
Just a decade ago, "Big Data" was a buzzword representing a novel challenge. Today, it's the bedrock of our digital world, silently powering everything from the shows Netflix recommends to the real-time fraud detection that protects your bank account. The core challenge remains the same: how to handle data that is too large, too fast, or too complex for traditional database systems.
The Modern Data Explosion
The scale of data generation is difficult to comprehend. As of 2024, it's estimated that the world will generate 181 zettabytes of data by 2025. A single zettabyte is 10^21 bytes, or one sextillion bytes. To put that in perspective, it's the equivalent of every person on Earth taking over 30,000 photos per second for an entire year. The next level of scale, a yottabyte, is 10^24 bytes.
A huge portion of this data is unstructured, generated by sources like:
- High-definition video: Streaming services, social media uploads, and surveillance footage.
- IoT (Internet of Things) sensors: Data from smart homes, industrial machinery, and autonomous vehicles.
- Social media and user-generated content: Billions of posts, images, and videos created daily.
This isn't just abstract—it's happening every single minute.
What Happens in an Internet Minute (2024)?
- 5.9 million Google searches are conducted.
- 138.9 million Reels are played across Facebook and Instagram.
- 1.04 million messages are exchanged on Slack.
- 229 million minutes are spent in Microsoft Teams meetings.
This constant flood of information from social media, IoT sensors, financial transactions, and scientific research requires a new generation of tools and techniques to store, process, and analyze it effectively.

Caption: This infographic illustrates the staggering volume of data generated globally every single minute as of 2024.
The Guiding Principles: 4 V's of Big Data
To understand the challenges of Big Data, we use a framework known as the "Four V's":
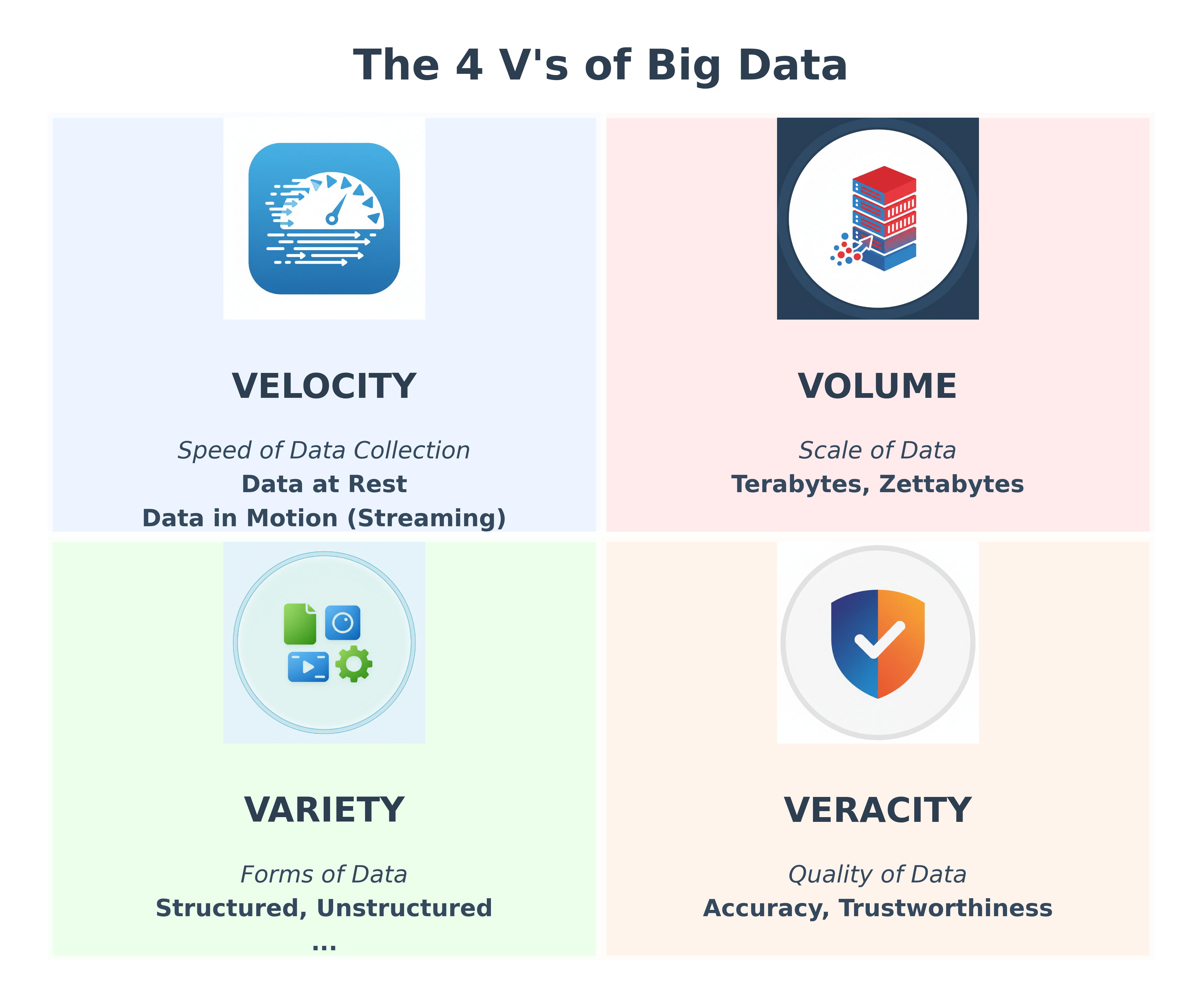
Volume
This refers to the sheer scale of data. We've moved from thinking in gigabytes and terabytes to petabytes and zettabytes. Storing and managing this much information efficiently is the first major hurdle.
Velocity
This is the speed at which new data is generated and needs to be processed. Stock market data, social media trends, and sensor logs from autonomous vehicles require real-time or near-real-time analysis to be valuable.
Variety
Data no longer fits into neat rows and columns. It can be:
- Structured: Traditional relational databases (e.g., customer tables).
- Semi-structured: JSON, XML, log files.
- Unstructured: Text documents, images, videos, audio files. A modern big data system must be able to handle all of these formats seamlessly.
Veracity
This refers to the quality and trustworthiness of the data. With so many data sources, ensuring accuracy and consistency is a major challenge. The quality of data is dependent on factors such as where it was collected, how it was collected, and how it will be analyzed. The veracity of data dictates how reliable and significant it truly is, as poor quality data leads to poor analysis and incorrect conclusions.
The Scalability Challenge
Handling the "Four V's" requires systems that can scale. In traditional computing, we often rely on Vertical Scalability, but for Big Data, Horizontal Scalability is the only viable path.
Vertical vs. Horizontal Scalability
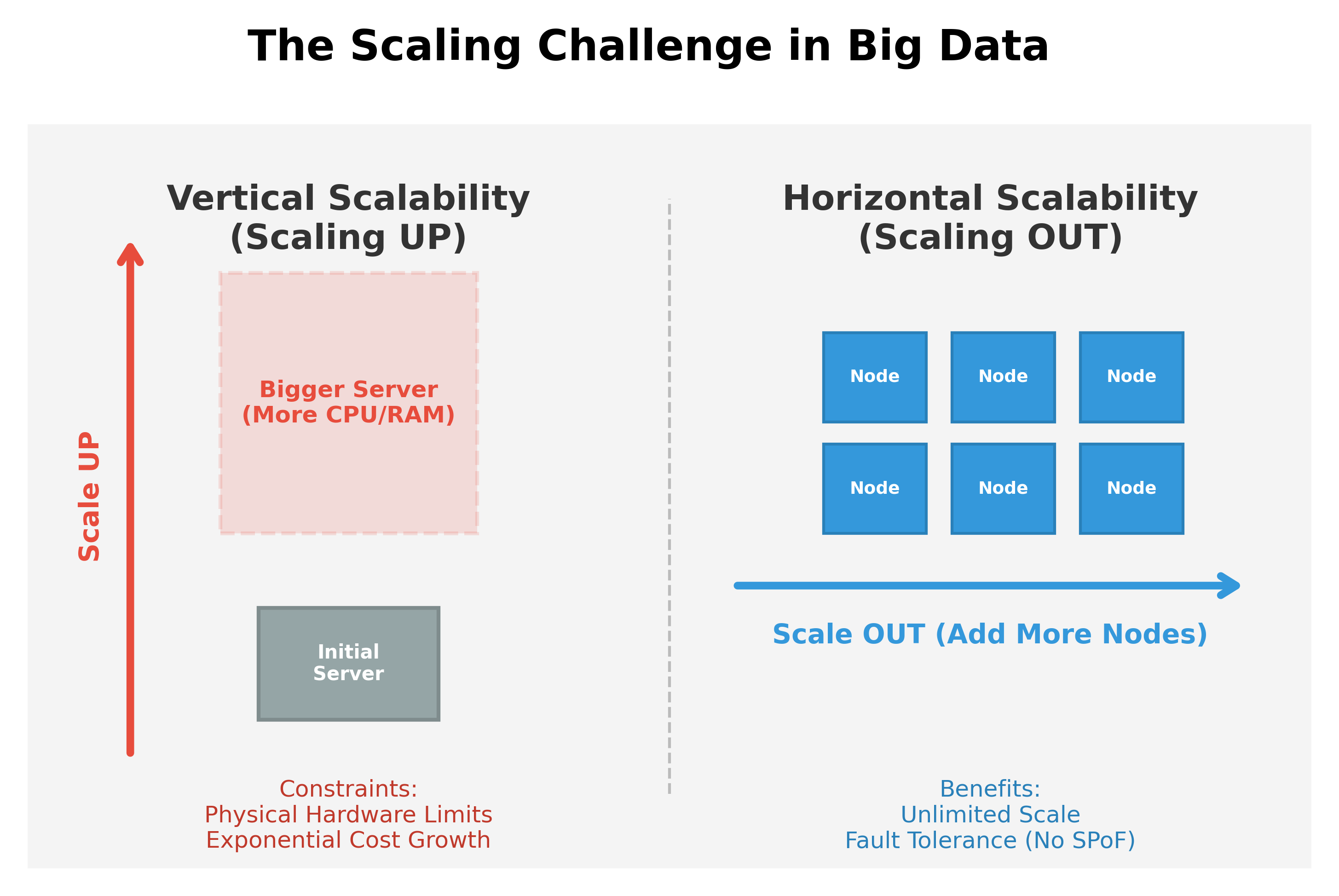
Vertical Scalability (Scaling Up)
Vertical scaling involves adding more power (CPU, RAM, or Disk) to an existing server. While simple to implement, it has severe constraints:
- Physical Limits: There is a maximum amount of hardware you can pack into a single machine. Once you hit the ceiling of the most powerful server available, you can no longer scale.
- Exponential Cost: The price of high-end hardware increases exponentially, not linearly. Doubling the power of a single machine often costs much more than double the price.
- Single Point of Failure: If your one massive server fails, your entire system goes down.
- Downtime: Upgrading hardware usually requires taking the server offline.
Horizontal Scalability (Scaling Out)
Horizontal scaling involves adding more machines (nodes) to a cluster and distributing the workload across them. This is the cornerstone of Big Data for several reasons:
- Unlimited Potential: You can keep adding commodity hardware indefinitely to handle growth.
- Cost-Effectiveness: It is far cheaper to use many "commodity" servers than one "super-computer."
- Fault Tolerance: If one node in a cluster of 1,000 fails, the system continues to operate, and the work can be redistributed.
- No Downtime: You can add or remove nodes from a cluster while it's still running.
Big Data frameworks like Hadoop and Spark were designed from the ground up to leverage horizontal scalability, allowing them to process petabytes of data across thousands of low-cost servers.
The Evolution of Big Data Processing
The tools for handling big data have evolved significantly.
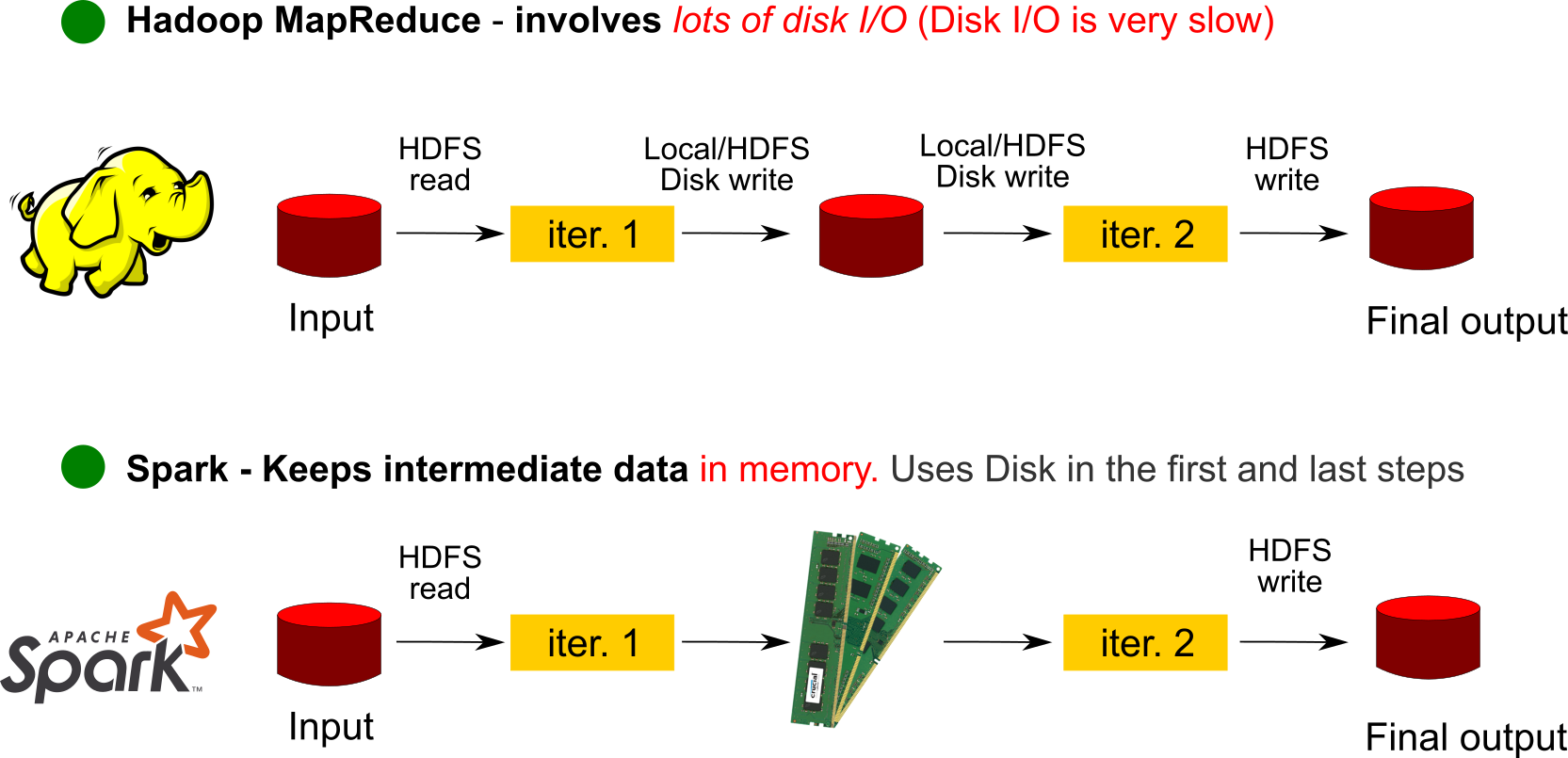
The Foundation: Hadoop
Initially, systems like Apache Hadoop pioneered the field. Hadoop provided two key components:
- HDFS (Hadoop Distributed File System): A way to store massive files across a cluster of commodity hardware.
- MapReduce: A programming model for processing these large datasets in a parallel and distributed manner.
While revolutionary, MapReduce was complex and slow for many use cases.
The Successor: Apache Spark
Apache Spark emerged as a faster, more flexible, and easier-to-use alternative. Spark performs most processing in-memory, which gives it a significant speed advantage over MapReduce's disk-based approach. It also provides a richer set of tools for various tasks:
- Spark SQL: For querying structured data.
- Spark Streaming: For real-time data processing.
- MLlib: For scalable machine learning.
Big Data Use Cases
Big data processing is no longer a niche capability; it's a driver of innovation across industries:
- Recommendation Engines: Services like Netflix, Spotify, and Amazon analyze your viewing/listening/browsing history in real-time to suggest what you might like next.
- Personalized Medicine: Genomic sequencing generates massive datasets that are analyzed to understand diseases and develop personalized treatments.
- Financial Services: Banks use big data to analyze market trends, manage risk, and detect fraudulent transactions in milliseconds.
- Logistics and Supply Chain: Companies like FedEx and UPS optimize delivery routes by analyzing real-time traffic data, weather conditions, and vehicle sensor data.
- Web Intelligence: Gauging consumer sentiment from social media, powering intelligent Q&A systems, and enabling large-scale image and facial recognition.
Tangible Benefits for Business
By leveraging modern data processing systems, organizations can move from simple reporting to predictive analytics and AI-driven decision-making. This translates into tangible benefits:
- Improved Customer Experience: Personalizing services and products to individual needs.
- Better, Fact-Based Decision Making: Using data to drive strategy instead of intuition.
- Increased Sales: Identifying new market opportunities and optimizing pricing.
- Reduced Risk: Detecting fraud and predicting operational failures before they happen.
- More Efficient Operations: Optimizing supply chains, logistics, and resource allocation.